

IT的に楽しむワールドカップ : 現代サッカーを分析するテクノロジーと指標

はじめに
眠れない日々が続いているのではないでしょうか。
そう。ワールドカップです。
私はスポーツ全般が大好きなので日本戦だけでなく、可能な限り多くの試合を視聴しています。
日本代表は果たしてどこまでいけるのでしょうか!執筆時点ではスウェーデン戦の2日前の夜中です。
さてさて。普段サッカーだけでなくスポーツ全般において、「知らない用語が増えたな」と感じることはありませんか?
野球で言えばバレルゾーンやWAR。サッカーで言えばxGやPPDAなど。
これらは簡単に言えば、選手の価値、能力、そして勝利への貢献度を客観的に表現するための指標です。
現代スポーツではテクノロジーの進歩により、ピッチ上のあらゆるデータを取得できるようになり、これまでは「感覚」で語られていたプレイを定量的に評価・計算できるようになりました。
MLBではABSによる判定が本格導入され、ワールドカップや欧州サッカーでも「1ミリでもボールがラインに残っているか」(三笘の1ミリ/チュニジアの逆1ミリ)を高精度センサーやカメラがミリ単位で判定するなど、テクノロジーの発展はスポーツのあり方に大きな変化をもたらしています。
そこで!今回は我々がアクセス可能な公開データとGoogle CloudのBigQueryを使ってサッカーの見える化を行い、あわせてBigQueryの強力な機能の数々をご紹介したいと思います。
データソースには StatsBomb のオープンデータを使います。StatsBombはスポーツデータ分析の専門企業で、W杯を含む多くの大会の詳細なプレイデータを無料で公開しています。
※重要:データは2022年カタール大会のデータになります。今大会のデータはまだ手に入れることができません。
1試合ごとに数千行に及ぶイベントデータ(パス・シュート・ドリブルなど)がJSON形式で手に入るので、エンジニアとしても分析のしがいがある最高の素材です。
利用ツールの説明
BigQueryについて
BigQueryは、Google Cloudが提供するフルマネージドでペタバイトスケールの超高速クラウドデータウェアハウスです。サーバーレス設計であるためインフラの構築や管理が一切不要で、SQLを使って大量のデータを一瞬で集計・分析することができます。
本プロジェクトでは、膨大なプレイデータを蓄積・解析する「脳」として機能します。さらに、集計したデータを直感的に理解するためのBIツール「Data Studio」との連携や、選手間の複雑なパスワークをネットワーク構造として分析する最新のグラフ分析機能「BigQuery Graph」など、高度な機能群も備わっており、データの価値を最大化してくれます。
StatsBombについて
StatsBombは、世界中のプロクラブやメディアに最先端のサッカーデータを提供するスポーツアナリティクスのリーディングカンパニーです。彼らは「StatsBombは、フットボールという競技への理解を深めるため、新しいデータや研究結果を公開し共有することにコミットする。あらゆるレベルにおける新しい研究や分析を積極的に推奨したい」という素晴らしい理念を掲げています。
この理念に基づき、ワールドカップをはじめとするメジャー大会の超高精度なプレイデータをオープンデータとしてGitHub上で無料公開しています。この高い志があるからこそ、我々のようなエンジニアでもプロさながらのデータ分析を手軽に体験できるようになっています。
データ連携と環境構築について
データ連携インポートの流れ
StatsBomb(GitHub公開データ)
↓ Python(statsbombpy)
DataFrame に整形
↓ google-cloud-bigquery
BigQuery へロード
↓
Data Studio で可視化
詳細なコードは一部省略しますが、全体のセットアップの流れは以下の通りです。
1. Google Cloud プロジェクトの用意
BigQueryを使うにはGCPプロジェクトが必要です。すでに開発用のプロジェクトがあればそちらを流用してください。なければ Google Cloud Console から新規作成します。
2. Pythonの仮想環境を作る
ライブラリのバージョン管理や環境のクリーンさを保つために、まずはPythonの仮想環境を用意します。
3. 必要なライブラリをインストール
今回使用するライブラリ一覧です。
| ライブラリ | 用途 |
|---|---|
| statsbombpy | StatsBombのオープンデータをPythonから簡単に取得するための公式ラッパー |
| google-cloud-bigquery | PythonからBigQueryをシームレスに操作するGCP公式クライアント |
| pandas | DataFrameによる柔軟なデータ整形・加工 |
| pyarrow | PandasのDataFrameをBigQueryにロードする際に内部で必要(忘れがちなので注意!) |
4. BigQueryにデータセットを作成する
BigQueryにデータを入れる前に、テーブルを格納するための「データセット」を作成しておきます。GCPの管理画面(GUI)でも作成できますが、gcloud CLIを使用すると一瞬で作成できます。
5. データロードスクリプトを書く
データ連携用に load_to_bq.py というスクリプトを用意しました。処理の流れは大きく以下の3段階です。
sb.matches()で全64試合のリストを取得sb.events()で全試合のイベントデータ(数万行)を取得・結合sb.lineups()で各試合のスターティングメンバーや選手情報を取得
from statsbombpy import sb
import pandas as pd
from google.cloud import bigquery
import json
PROJECT_ID = "your-gcp-project-id"
DATASET_ID = "statsbomb_wcup2022"
# 2022 FIFA World Cup: competition_id=43, season_id=106
COMPETITION_ID = 43
SEASON_ID = 106
client = bigquery.Client(project=PROJECT_ID)
def load_df_to_bq(df: pd.DataFrame, table_id: str) -> None:
table_ref = f"{PROJECT_ID}.{DATASET_ID}.{table_id}"
job_config = bigquery.LoadJobConfig(write_disposition="WRITE_TRUNCATE")
job = client.load_table_from_dataframe(df, table_ref, job_config=job_config)
job.result()
print(f" -> {table_ref} に {len(df)} 行をロードしました")
def serialize_complex_cols(df: pd.DataFrame) -> pd.DataFrame:
"""list/dict 型の列を JSON 文字列に変換(BQ の型エラー対策)"""
for col in df.columns:
if df[col].apply(lambda x: isinstance(x, (list, dict))).any():
df[col] = df[col].apply(
lambda x: json.dumps(x, ensure_ascii=False) if isinstance(x, (list, dict)) else x
)
return df
def main():
print("=== 試合リスト (matches) を取得中... ===")
matches = sb.matches(competition_id=COMPETITION_ID, season_id=SEASON_ID)
print(f" 対象試合数: {len(matches)} 試合")
matches = serialize_complex_cols(matches)
load_df_to_bq(matches, "matches")
print("\n=== イベントデータ (events) を取得中... ===")
match_ids = matches["match_id"].tolist()
all_events = []
for i, m_id in enumerate(match_ids, 1):
print(f" [{i}/{len(match_ids)}] match_id={m_id} を取得中...", end="", flush=True)
match_events = sb.events(match_id=m_id)
match_events["match_id"] = m_id
all_events.append(match_events)
print(f" {len(match_events)} 件")
df_events = pd.concat(all_events, ignore_index=True)
print(f" 総イベント数: {len(df_events)} 行")
df_events = serialize_complex_cols(df_events)
load_df_to_bq(df_events, "events")
print("\n=== ラインアップ (lineups) を取得中... ===")
all_lineups = []
for m_id in match_ids:
lineups = sb.lineups(match_id=m_id)
for team, lineup_df in lineups.items():
lineup_df["match_id"] = m_id
lineup_df["team"] = team
all_lineups.append(lineup_df)
df_lineups = pd.concat(all_lineups, ignore_index=True)
df_lineups = serialize_complex_cols(df_lineups)
load_df_to_bq(df_lineups, "lineups")
print("\n✅ 全テーブルのロードが完了しました!")
if __name__ == "__main__":
main()serialize_complex_cols がミソ
ハマりどころ:StatsBombデータにはネストされたオブジェクト型が多い
StatsBombのイベントデータには、location(座標情報)や pass(パスの詳細情報)など、Pythonの list や dict 型のまま格納されている複雑な構造の列が多数存在します。これらを加工せずにそのままBigQueryにロードしようとすると、スキーマ不一致で型エラーを吐いてしまいます。
今回は一番シンプルな解決策として、json.dumps() を使って一度丸ごと「JSON形式の文字列」にシリアライズして流し込んでいます。本格的に分析する場合は、ロード時にスキーマを厳密に定義してレコード型としてネスト展開する方法が理想ですが、「ひとまず動かして分析を始めてみる」という段階なら、この文字列変換アプローチが最も手軽でおすすめです。
6. スクリプトを実行する
全64試合のイベントデータをAPI経由で逐次取得するため、ロードの完了までには 10〜20分程度 かかります。実行中はコンソールに取得状況のログが流れるので、試合のハイライトでも見ながら待ちましょう📺️
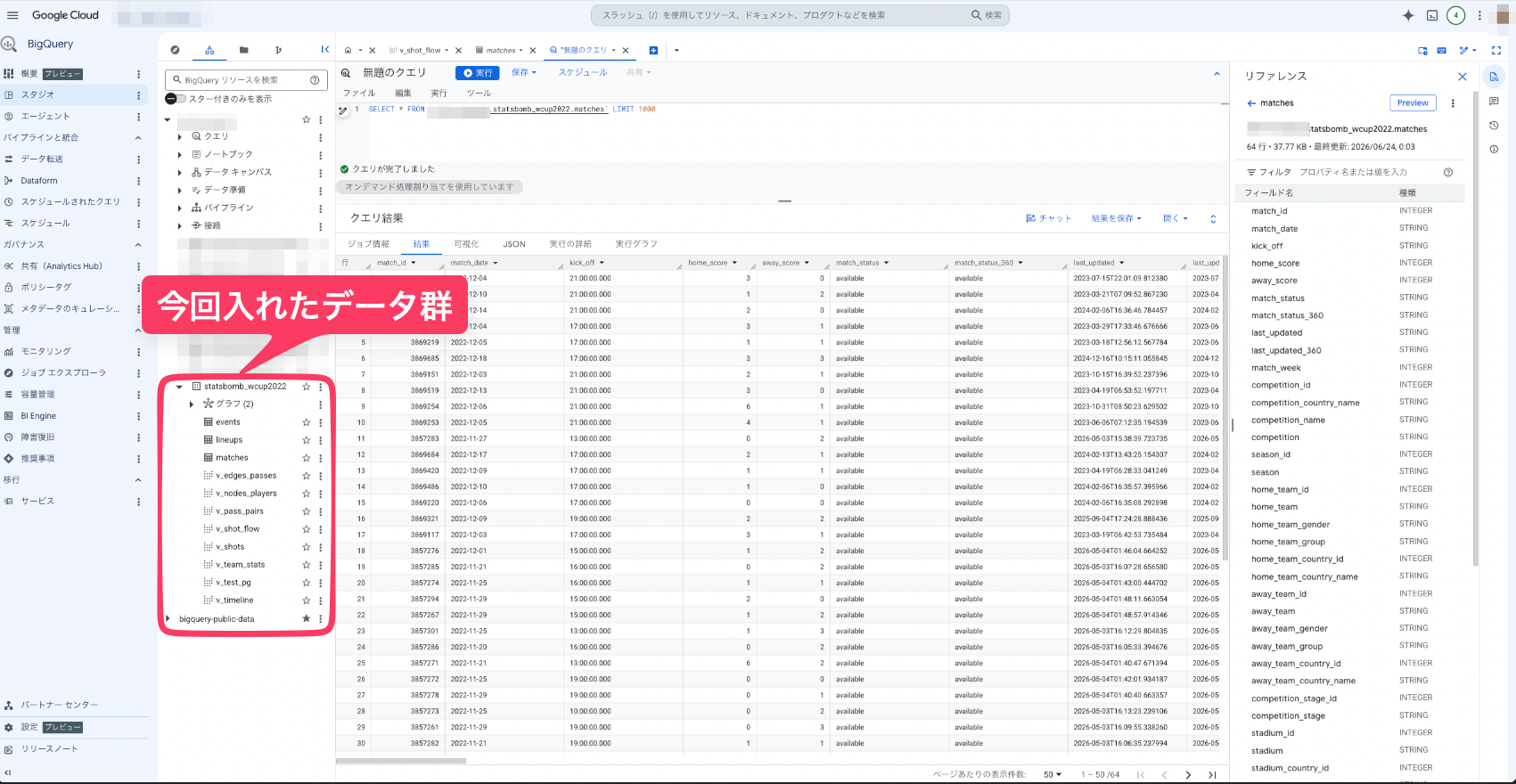
7. 完了後のBigQueryの状態
ロードが完了すると、BigQueryのデータセット statsbomb_wcup2022 内に以下の3つのテーブルが自動生成されます。
| テーブル名 | 内容 | 行数 |
|---|---|---|
| matches | 試合一覧(日程、対戦カード、スコア、会場スタジアムなど) | 64行 |
| events | 全試合の全プレイイベント(パス、シュート、タックルなどのログ) | 234,637行 |
| lineups | 各試合のスターティングメンバー、ポジション、途中交代情報 | 3,244行 |
今後の分析は、この23万行を超える膨大なログが格納された events テーブルを中心に行っていきます。type カラムに "Pass" や "Shot" といったイベント種別が格納されているため、これをフックにして様々な切り口でSQLクエリを投げていきます。
テーブル分析
分析基盤が整ったので、さっそくBigQueryにQuery(SQL)を投げてサッカーのデータを丸裸にしていきましょう!
分析1:チーム別シュート統計
まずはシンプルに「どのチームが最もシュートを打ち、決定力が高かったのか」を算出してみます。
SELECT
team,
COUNT(*) AS shots,
COUNTIF(shot_outcome = 'Goal') AS goals,
ROUND(AVG(CAST(shot_statsbomb_xg AS FLOAT64)), 3) AS avg_xg
FROM `your-gcp-project-id.statsbomb_wcup2022.events`
WHERE type = 'Shot'
GROUP BY team
ORDER BY shots DESC
LIMIT 15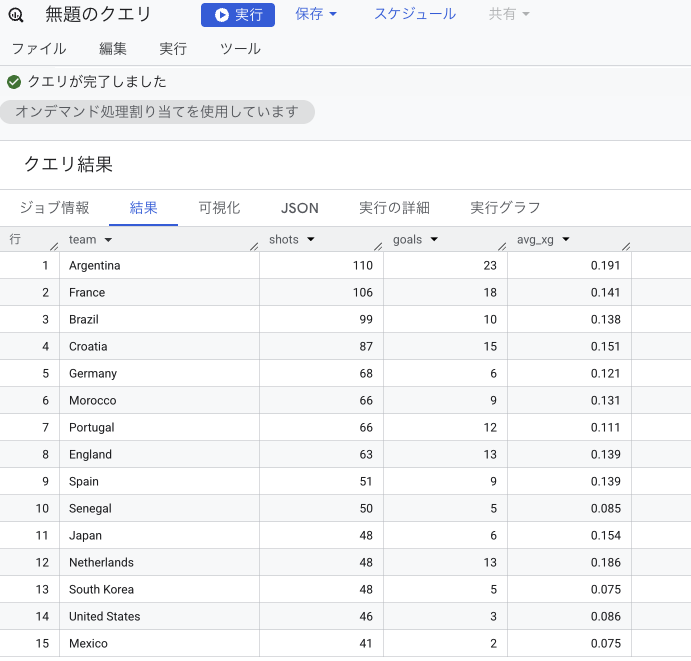
結果:
| team | shots | goals | avg_xg |
|---|---|---|---|
| Argentina | 110 | 23 | 0.191 |
| France | 106 | 18 | 0.141 |
| Brazil | 99 | 10 | 0.138 |
| Croatia | 87 | 15 | 0.151 |
| Germany | 68 | 6 | 0.121 |
| Morocco | 66 | 9 | 0.131 |
| Portugal | 66 | 12 | 0.111 |
| England | 63 | 13 | 0.139 |
| Spain | 51 | 9 | 0.139 |
| Senegal | 50 | 5 | 0.085 |
| Japan | 48 | 6 | 0.154 |
| Netherlands | 48 | 13 | 0.186 |
| South Korea | 46 | 5 | 0.075 |
| United States | 46 | 3 | 0.086 |
| Mexico | 41 | 2 | 0.075 |
着目ポイント:
- アルゼンチンはシュート110本、23ゴールと他を圧倒。さらに avg_xg (平均ゴール期待値)も 0.191 とずば抜けて高く、「強引に打つのではなく、極めて質の高い決定的なシチュエーションを作ってからシュートを打てていた」ことがデータから証明されています。
- ブラジルはシュートを99本打っているものの、ゴール数はわずか10。決定力不足が数字にも顕著に表れており、クロアチアに延長戦の末に敗れた要因の一つを物語っています。
- モロッコはシュート数が強豪ドイツやポルトガルと同数でありながら、ベスト4に進出。堅固な守備ブロックをベースに、少ないチャンスを高確率で仕留める「ソリッドな堅守速攻スタイル」がそのまま数字に出ています。
- 日本代表はシュート本数こそ全体11位タイ(48本)ですが、平均xGは 0.154 と全体4位。少ないチャンスでも、高い集中力でゴールの可能性が極めて高いエリアへ侵入してシュートに繋げていたことが分かります。
分析2:チーム別パス成功率ランキング
続いて、現代サッカーにおいてポゼッション(支配率)の指標となるパスの成功率を見てみましょう。StatsBombでは「パスが成功した場合は pass_outcome カラムが NULL になる」というデータ構造の仕様があるため、IS NULL を用いて成功数を集計します。
SELECT
team,
COUNT(*) AS passes,
COUNTIF(pass_outcome IS NULL) AS completed,
ROUND(COUNTIF(pass_outcome IS NULL) / COUNT(*) * 100, 1) AS completion_rate
FROM `your-gcp-project-id.statsbomb_wcup2022.events`
WHERE type = 'Pass'
GROUP BY team
ORDER BY passes DESC
LIMIT 10結果:
| team | passes | completed | completion_rate |
|---|---|---|---|
| Argentina | 4,615 | 3,939 | 85.4% |
| Croatia | 4,511 | 3,796 | 84.1% |
| France | 3,926 | 3,291 | 83.8% |
| Spain | 3,914 | 3,540 | 90.4% |
| England | 3,238 | 2,800 | 86.5% |
| Brazil | 3,196 | 2,776 | 86.9% |
| Portugal | 3,129 | 2,655 | 84.9% |
| Netherlands | 3,005 | 2,501 | 83.2% |
| Morocco | 2,865 | 2,292 | 80.0% |
| United States | 2,201 | 1,822 | 82.8% |
着目ポイント:
- スペインのパス成功率 90.4% が異常なほど突出しています。総パス数3,914本(全体4位)を記録しながら9割以上を正確に繋ぎ続けるという、ピッチを完全に支配する圧倒的なポゼッションサッカースタイルが視覚化されています。
- ちなみに日本代表は、このランキングではパス本数で16位、成功率では25位という結果でした。ここから次の分析へと深掘りしていきます。
分析3:日本代表の試合ごとの成績推移
日本代表に焦点を絞り、試合ごとのスタッツを時系列で追ってみます。events テーブルと matches テーブルを match_id で JOIN することで、対戦相手や実際のスコアを並べて可視化できます。
SELECT
m.match_date,
CASE WHEN e.team = m.home_team
THEN m.away_team
ELSE m.home_team
END AS opponent,
m.home_score,
m.away_score,
COUNT(*) AS passes,
ROUND(COUNTIF(e.pass_outcome IS NULL) / COUNT(*) * 100, 1) AS completion_rate
FROM `your-gcp-project-id.statsbomb_wcup2022.events` e
JOIN `your-gcp-project-id.statsbomb_wcup2022.matches` m
ON e.match_id = m.match_id
WHERE e.type = 'Pass'
AND e.team = 'Japan'
GROUP BY m.match_date, opponent, m.home_score, m.away_score
ORDER BY m.match_date結果:
| match_date | opponent | score | passes | completion_rate |
|---|---|---|---|---|
| 2022-11-23 | Germany | 2-1 ✅ | 294 | 73.1% |
| 2022-11-27 | Costa Rica | 0-1 ❌ | 619 | 85.1% |
| 2022-12-01 | Spain | 2-1 ✅ | 253 | 70.0% |
| 2022-12-05 | Croatia | 1-1 (PK負け) | 582 | 74.9% |
着目ポイント:
- 歴史的勝利を収めたドイツ戦・スペイン戦では、パス総数が 250〜290本台 と極端に少なく、成功率も70〜73%に留まっています。これは、主導権をあえて相手に渡して自陣で耐え忍び、一瞬の隙を突く電撃的な「リアクションサッカー」を完璧に遂行していたことを示しています。
- 対照的に、敗戦したコスタリカ戦ではパス総数が「619本」、成功率「85.1%」と非常に高い数値を記録しています。主導権を握って「ボールを持たされた」結果、相手の堅いブロックを崩しきれずカウンターに沈むという、当時の日本代表が直面した崩しの課題が数字からまざまざと伝わってきます。
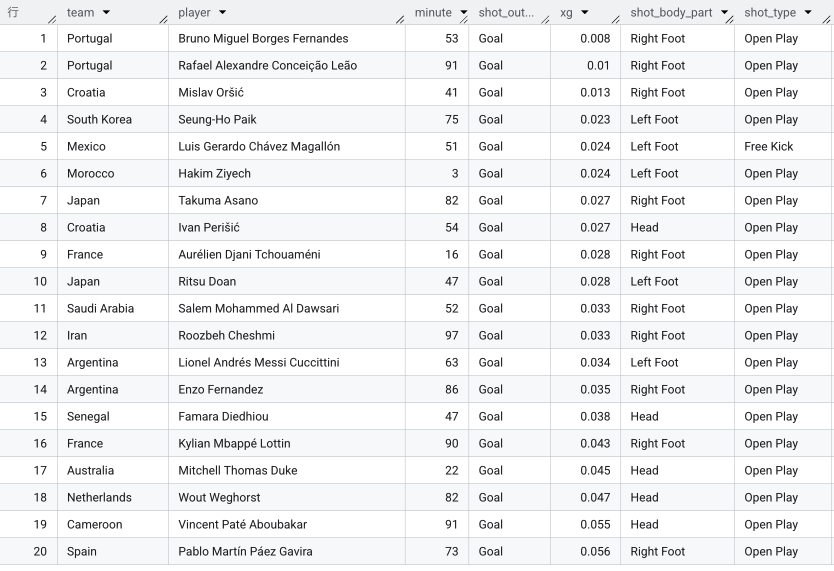
分析4:xG0.5超えの「決定的チャンス」ランキング
次に、大会を通して最も「決まるべきだった(ゴールに極めて近かった)シュート」のトップ10を見てみます。ゴール期待値(xG)が 0.5 以上というのは、「同じシチューションで2回打てば1回は必ず決まる」とされる絶対的な決定機です。
SELECT
team, player, minute,
shot_outcome,
ROUND(CAST(shot_statsbomb_xg AS FLOAT64), 3) AS xg,
shot_body_part,
shot_type
FROM `your-gcp-project-id.statsbomb_wcup2022.events`
WHERE type = 'Shot'
AND CAST(shot_statsbomb_xg AS FLOAT64) >= 0.5
ORDER BY xg DESC
LIMIT 10結果:
| team | player | minute | shot_outcome | xg | shot_body_part | shot_type |
|---|---|---|---|---|---|---|
| Serbia | Aleksandar Mitrović | 52 | Goal | 0.897 | Right Foot | Open Play |
| Cameroon | Jean-Charles Castelletto | 28 | Goal | 0.895 | Right Foot | Open Play |
| Japan | Ao Tanaka | 50 | Goal | 0.873 | Other | Open Play |
| France | Randal Kolo Muani | 78 | Goal | 0.852 | Right Foot | Open Play |
| Ecuador | Enner Valencia | 48 | Goal | 0.791 | Right Foot | Open Play |
| Germany | İlkay Gündoğan | 32 | Goal | 0.783 | Right Foot | Penalty |
| Iran | Mehdi Taremi | 102 | Goal | 0.783 | Right Foot | Penalty |
| Portugal | Cristiano Ronaldo | 64 | Goal | 0.783 | Right Foot | Penalty |
| Argentina | Lionel Messi | 72 | Goal | 0.783 | Left Foot | Penalty |
| Canada | Alphonso Davies | 10 | Saved | 0.783 | Left Foot | Penalty |
トップ10のうち9本がゴールに結びついています。期待値が極めて高いシーンでのシュートがいかに高確率で決まるかを裏付ける結果ですが、カナダのアルフォンソ・デイヴィス選手がPKをGKに防がれたプレイのみが唯一の「未ゴール」例外となっています。
そして注目すべきは、日本代表の田中碧選手が堂々の第3位(xG: 0.873)にランクインしている点です。スペイン戦の後半、あの「三笘の1ミリ」から折り返された奇跡のボールを押し込んだ逆転ゴールは、統計的にも「絶対に決めるべき超決定機」だったことが分かります。さらに、使用部位(shot_body_part)が "Other"(その他)になっているのも非常に面白いポイントです。これは足や頭ではなく、お腹や胸、膝などのイレギュラーな部位で押し込んだことを示しており、あの泥臭く、執念で滑り込んで体ごと押し込んだ「魂のゴール」そのものがデータとして記録されている証拠です。
ちなみに、この逆のクエリ(「最もxG(ゴール期待値)が低かったにもかかわらず決まった、超高難易度のゴール一覧」)を出すことも可能です。いわば「ワールドカップ・スーパーゴラッソランキング」になりますが、ドイツ戦でニア上に突き刺した浅野拓磨選手の異次元のゴールは、この低期待値ゴールランキングで世界第7位に輝いています。気になる方はぜひ映像で見返してみてください!
分析5:xA(アシスト期待値)
xGが「シュートを打った選手の決定機の質」を測るのに対し、xAは「キーパスを出した選手がどれだけ高品質なチャンスを作ったか」を評価する指標です。受け手がシュートを外しても出し手の評価は下がらないため、「アシスト数」という結果論では見えない貢献が数値化されます。
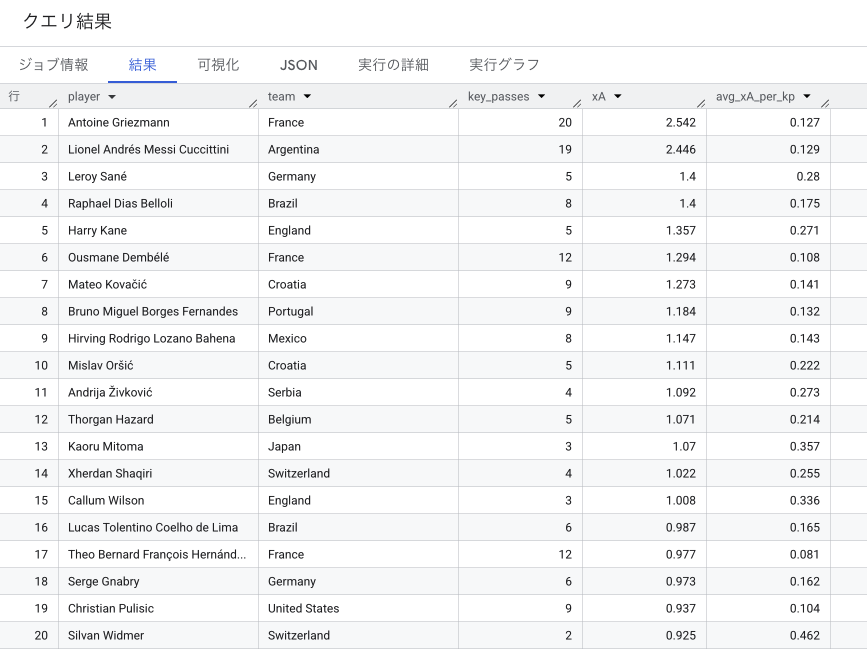
グリーズマンとメッシの圧倒的な数字が出てますね。そりゃこの2チームが決勝に残るよな、といった感想になります。
分析6:PPDA(プレッシング強度)
PPDA(Passes per Defensive Action)はチームの前線プレッシングの強度を測る世界標準の指標です。「相手に1本パスを通されるまでに、自チームが何回守備アクション(プレッシャー・タックル・インターセプト・ファウル)を起こしたか」の逆数に当たります。値が低いほど激しいプレッシングを意味します。
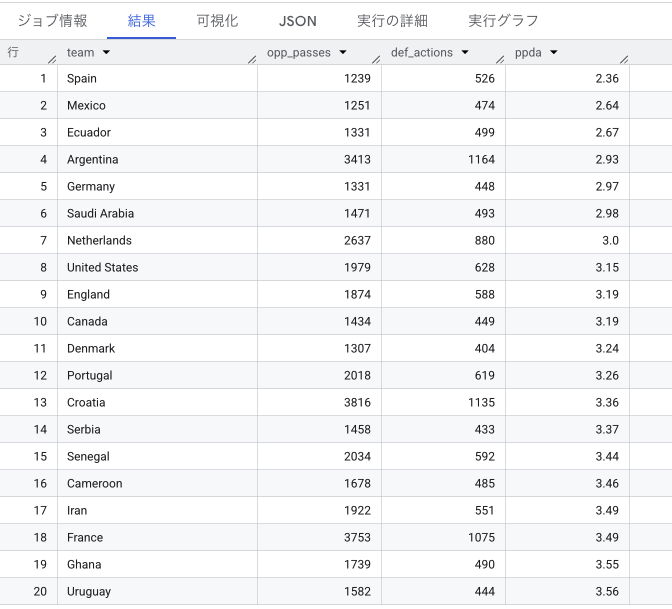
プレス全体だと意外と日本は入ってきません。ただ前プレのみなど条件を加えた場合はまた数字が変わってくるかもしれませんね。
分析7:xG Chain(xGチェーン)
xG Chain は「シュートで終わった一連の攻撃の組み立てに関わったすべての選手に、そのシュートのxG値を分配する」指標です。
| 指標 | 誰が評価されるか |
|---|---|
| xG | シュートを打った選手 |
| xA | ラストパスを出した選手 |
| xG Chain | シュートに至る組み立て全員(CB・ボランチも含む) |
「地味だが試合を作るセンターバック」や「アシストこそないが攻撃の起点になるアンカー」を発見できます。
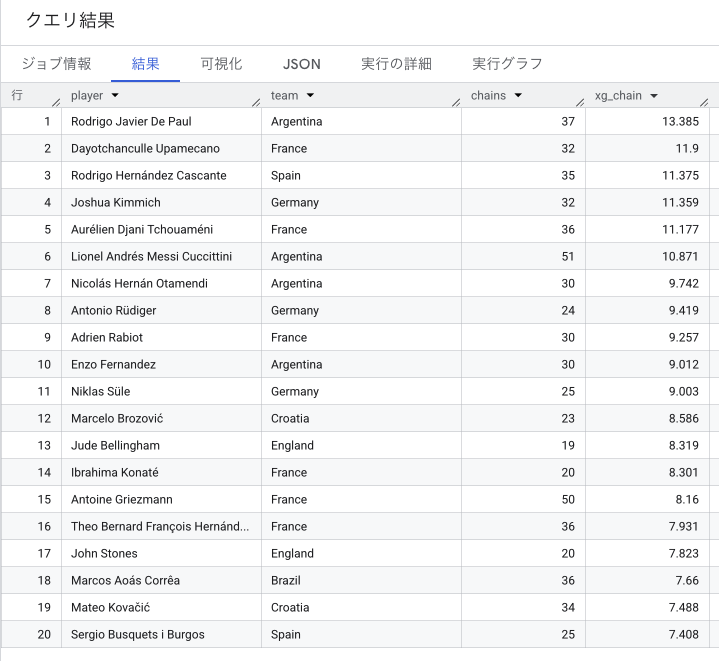
デパウルはかなりそのイメージありましたよね。納得の数字です。
ビジュアル分析する(Data Studio連携)
BigQueryでデータをこねくり回すだけでも十分楽しいですが、ここからはData Studio(Googleが提供する無料のインタラクティブBIツール)を利用して、データに命を吹き込んで可視化していきましょう。Data Studioを使えば、BigQueryに格納したデータをノーコードかつマウス操作だけで美麗なグラフやマップに変換し、インタラクティブに共有することができます。
事前準備:Data Studio用のビューを作る
23万行・100列を超える生の events テーブルをData Studioから毎回直接スキャンすると、クエリコスト(データスキャン量)がかさみ、描画のパフォーマンスも低下してしまいます。そこで、必要なデータのみをあらかじめ集計した軽量な「ビュー(View)」をBigQuery側に作成しておきます。今回は以下の3つのビューをデータベース内に構築しました。(詳細は省略)
-- 1. シュートマップ用(シュートの座標・結果・xGを抽出)
CREATE OR REPLACE VIEW `your-gcp-project-id.statsbomb_wcup2022.v_shots` AS
-- どの位置から誰がシュートを放ち、結果がゴールになったかを抽出するビュー
-- 2. チーム別スタッツ集計(試合結果、シュート総数、合計期待値など)
CREATE OR REPLACE VIEW `your-gcp-project-id.statsbomb_wcup2022.v_team_stats` AS
-- 各チームの主要スタッツを集約するビュー
-- 3. タイムライン集計(時間帯別のイベント発生数など)
CREATE OR REPLACE VIEW `your-gcp-project-id.statsbomb_wcup2022.v_timeline` AS
-- 試合の中の時間帯ごとの傾向を可視化するためのビューData Studio への接続手順
接続の流れは非常にシンプルで、ノーコードで完結します。
- Data Studio を開き、「空のレポート」 を作成
- コネクタ一覧から 「BigQuery」 を選択
- 自身のプロジェクト → 作成したデータセット
statsbomb_wcup2022を選び、上記の各ビューを選択して「追加」
作成したダッシュボードは、Webページ埋め込み用のiframeコードを簡単に生成できます。今回は実際に可視化したレポートをいくつか共有します。
グラフ1:シュートマップ散布図(ピッチ上の位置可視化)
使用ビュー:v_shots
2022年大会で放たれたすべてのシュートの座標データを、サッカーピッチの背景にマッピングした散布図です。
※リンクをお試しください。
https://datastudio.google.com/s/iOTA0FEEcMM

読み取りポイント:
- プロットされた円が大きいほど、ゴールに繋がる確率が高かった「xG(期待値)の高いシュート」であることを意味します。
- ゴールから遠い位置にある非常に小さなサークル(xGが極めて低いプロット)でありながら「Goal」判定になっているものこそ、観客を熱狂させたロングシュートや「ゴラッソ」です。
グラフ2:チーム別シュート数と平均xGの2軸散布図
使用ビュー:v_team_stats
https://datastudio.google.com/reporting/4dc5ac0e-7774-45fc-9ce0-bf248dfff02c
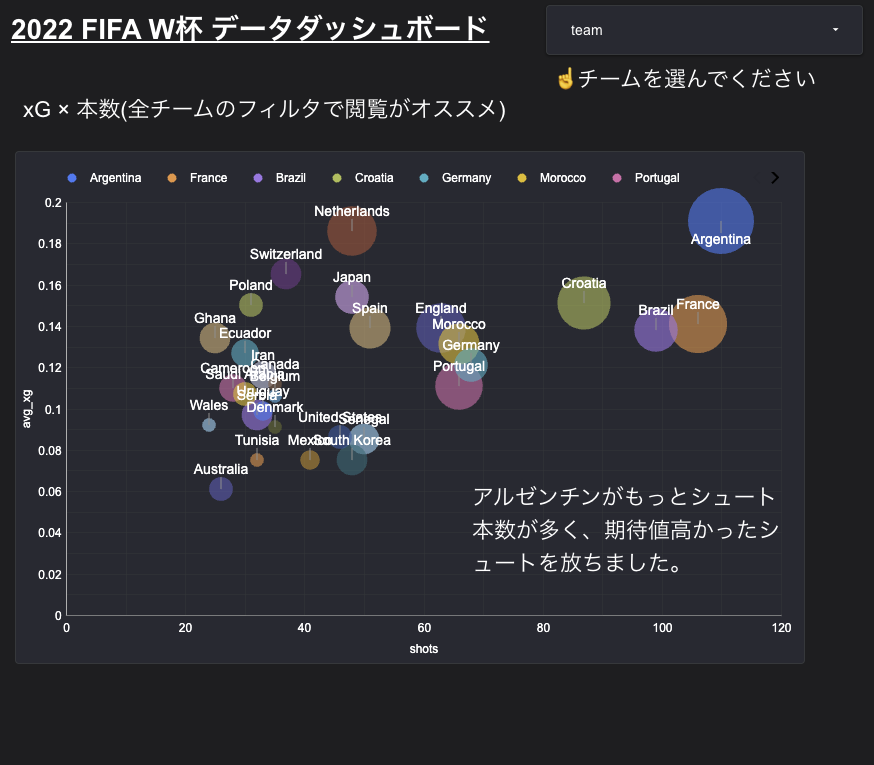
「シュートの量(数)」を横軸、「シュートの質(平均期待値)」を縦軸に配置し、さらにバブルの大きさで「総得点数」を表現したバブルチャートです。これにより各チームの攻撃キャラクターが綺麗に4象限に分類されます。
読み取りポイント:
- 右上(シュート数も多く、質も高い「最強ゾーン」):優勝したアルゼンチンがここに位置しています。圧倒的な攻撃の分厚さを象徴しています。
- 右下(シュート数は多いが、平均期待値が低い「力押しゾーン」):ミドルシュートなどの遠い位置からの積極的な仕掛けが多いブラジルなどのスタイルが該当します。
- 左上(シュート数は少ないが、1本あたりの質が極めて高い「省エネ・ワンチャンスゾーン」):手数の少ないカウンターで奇跡を演出したモロッコがここに位置しており、戦術的な個性が見事に可視化されています。
グラフ3:試合時間帯別ファウル数とゴール数の複合折れ線グラフ
使用ビュー:v_timeline
試合開始からアディショナルタイム(前後半の終盤)まで、何分にイベントが発生しやすいかを時系列に並べたグラフです。
https://datastudio.google.com/reporting/0f22f785-5992-431c-a178-a7e505bd3743
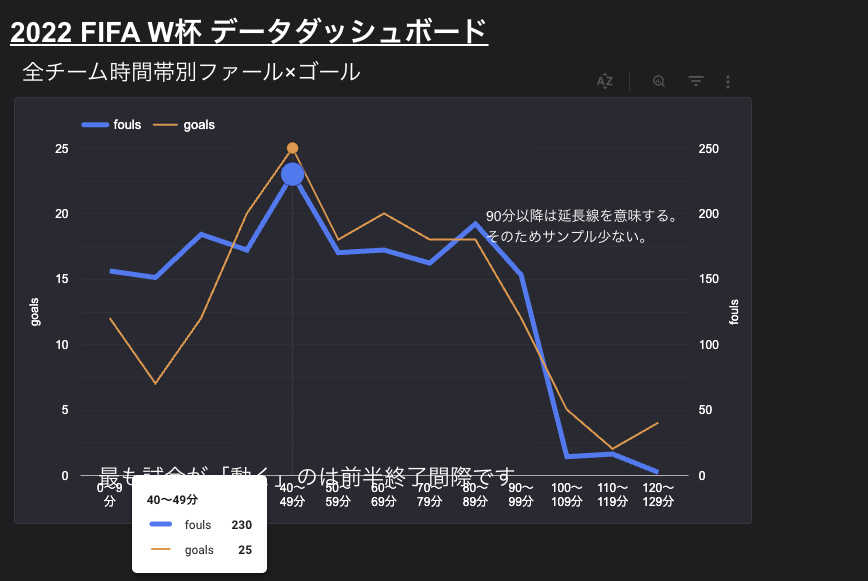
データの傾向から読み取れること:
- 40〜49分にファウル数(fouls)とゴール数(goals)が同時にスパイク(急上昇):前半終了の間際は、スタミナ低下や戦術の焦りからプレイが激化し、試合が急激に動いて荒れやすい展開になることがデータに如実に表れています。
- ゴール数は30〜49分と70〜89分に大きな山がある:前後半それぞれの「中盤から終盤にかけて」得点が大きく動きやすいという、サッカーファンがおおよそ肌感覚で持っている展開の起伏がデータで実証されています。
- 90分〜99分以降(延長戦・アディショナルタイム)のデータ急減:これはサンプル数の兼ね合い(全64試合のうち、延長戦までもつれ込んだ試合数のみが対象になるため)による急落です。
グラフ4:サンキーダイアグラムによるシュートプロセスの視覚化
使用ビュー:v_timeline
「放たれたシュートがどのようなプロセスを経由してゴール、あるいは枠外へと至ったか」の流れの太さをビジュアルで示した図です。Data Studioの仕様上、同時にマッピングできるディメンションは2階層までですが、シュートの起点から結末までのフローを直感的に把握できます。
https://datastudio.google.com/reporting/726060b2-53a5-4e26-9126-8a893a0a910b
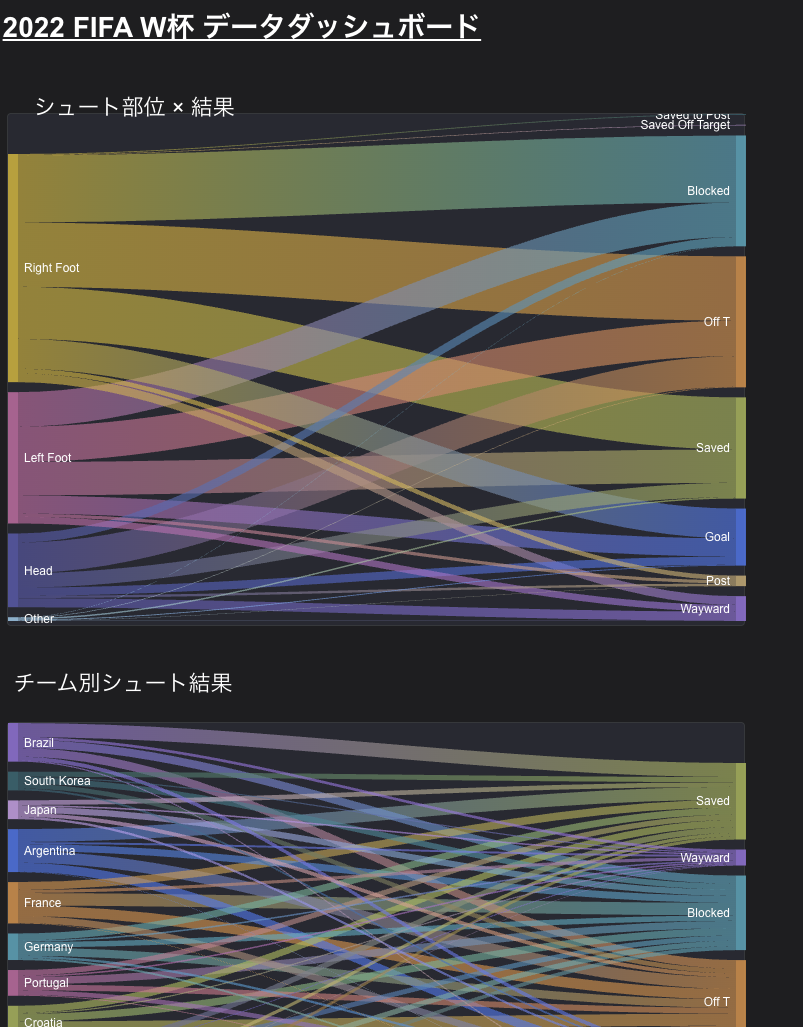
可視化された流れから読み取れる事実:
- シュートパターンの傾向:
- Open Play(通常の流れの中からのシュート) が大半を占め、その大部分が Right Foot(右足) で打たれています。右利きプレイヤーが圧倒的多数を占めるサッカーの基本構図そのものです。
- Penalty(PK) はほぼ100%が Right Foot からまっすぐ Goal へと太いラインで結ばれており、PKという決定機の凄まじい成功率の高さが視覚的に理解できます。
- Head(ヘディングシュート) は、他の足元のシュートと比較して Saved(GKセーブ) や Off T(枠外) に流れる帯の割合が有意に太く、ヘディングでの得点難易度の高さがデータに裏付けられています。
- 国別によるシュート成功のプロセス比率:
- アルゼンチンは、放ったシュートの帯からゴールに直結する帯への「変換率」が他チームより太く、チャンスをモノにする決定力の高さが視覚的にも証明されています。
- 日本は全体のパスやシュート数が控えめな帯の細さですが、ゴールへ到達している比率は相対的にかなり太く、驚異的なワンチャンスへの集中力でグループリーグを突破した軌跡がデータに映り込んでいます。
BigQuery Graphを使った最新パス分析
ここからは、本記事における最も「IT的」でエキサイティングな最新機能、BigQuery Graph(BQ Graph)を用いた分析にチャレンジしてみましょう!
BigQuery Graph とは
BigQuery Graphは、BigQueryにネイティブに組み込まれたリレーショナルデータのためのグラフデータベース機能です。ここでいう"Graph"は先程のビジュアルでみた「グラフ」と違い数学的な"Graph"です。サッカーにおけるパス回しは、選手を「ノード(点)」、選手間のパスを「エッジ(線)」として捉えることで、1つの巨大な「ネットワーク(グラフ構造)」として表現できます。BigQuery Graphでは、この選手同士の関係性を記述するために、標準化されたグラフクエリ言語規格である SQL-PGQ (Property Graph Query) の記述方法を利用できます。これがパスワーク分析において非常に強力に作用します。
なぜ普通のSQLではなくGraph(GQL)なのか?
例えば、サッカーの戦術分析でよくある「A選手 → B選手 → C選手 → D選手 とダイレクトに4人でパスを繋ぎきったパスルートをすべて抽出する」という処理を、従来のRDB(通常のSQL)で書こうとすると以下のように自己結合(Self JOIN)を幾重にも重ねる地獄のようなコードになります。
-- 通常のSQL:何度も同じテーブルを自己JOINする必要があり、メンテナンスも解読も困難
SELECT e1.player, e2.player, e3.player, e4.player
FROM events e1
JOIN events e2 ON e1.pass_recipient_id = e2.player_id AND e1.match_id = e2.match_id
JOIN events e3 ON e2.pass_recipient_id = e3.player_id AND e2.match_id = e3.match_id
JOIN events e4 ON e3.pass_recipient_id = e4.player_id AND e3.match_id = e4.match_id
WHERE e1.type = 'Pass' AND e2.type = 'Pass' AND e3.type = 'Pass'
AND e1.timestamp < e2.timestamp AND e2.timestamp < e3.timestamp一方で、BigQuery Graph(SQL-PGQ構文)を用いると、以下のようなアロー(矢印)表記を組み込んだ MATCH 句で直感的に表現できます。
MATCH (p1:Player)-[e1:Pass]->(p2:Player)-[e2:Pass]->(p3:Player)-[e3:Pass]->(p4:Player)わずか 1行 です!繋ぎの深さが4人、5人と増えた場合でも、末尾にアローを伸ばして定義を追加するだけ。コードの可読性と美しさが圧倒的に向上します。
構築手順
非常にシンプルな流れでグラフデータベース化することができます。
STEP 1:ノード・エッジビューの作成
BigQuery Graphを宣言するために、まずは選手(点:ノード)とパスの記録(線:エッジ)の2つの情報を、テーブルまたはビューとして切り出します。
-- ノード(選手一覧)を定義するビューを作成
CREATE OR REPLACE VIEW `your-gcp-project-id.statsbomb_wcup2022.v_nodes_players` AS
-- 選手情報を一意に取り出すクエリSTEP 2:Property Graph の定義
定義したノードとエッジのビューを、BigQueryに「このデータ同士は繋がっているグラフ構造である」と認識させる宣言(定義)を投げます。
CREATE OR REPLACE PROPERTY GRAPH `your-gcp-project-id.statsbomb_wcup2022.soccer_pass_graph`
NODE TABLES (
`your-gcp-project-id.statsbomb_wcup2022.v_nodes_players`
)
EDGE TABLES (
`your-gcp-project-id.statsbomb_wcup2022.v_edges_passes`
);Graphによるパス回しのネットワーク分析
セットアップが完了したら、グラフ専用の GRAPH_TABLE 関数を使って分析クエリを走らせていきましょう。
グラフ分析1:チームのパス配給ハブ選手ランキング
「ピッチ上で最もパスを配給し、チームのビルドアップ(攻撃の組み立て)の心臓として君臨していたハブ選手」をカウントします。
SELECT player_name, team_name, COUNT(*) AS total_passes
FROM GRAPH_TABLE(
`your-gcp-project-id.statsbomb_wcup2022.soccer_pass_graph`
MATCH (p:Player)-[e:Pass]->()
COLUMNS(p.player_name, p.team_name)
)
GROUP BY player_name, team_name
ORDER BY total_passes DESC
LIMIT 15;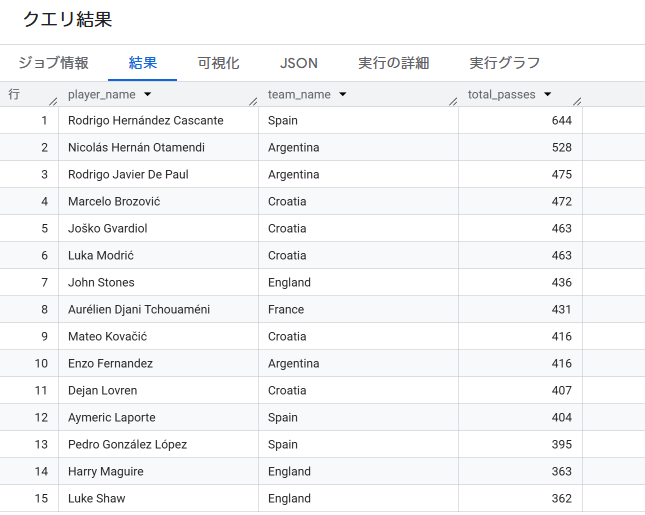
結果(大会全体のハブ選手上位10名):
| player_name | team_name | total_passes |
|---|---|---|
| Rodrigo Hernández Cascante | Spain | 644 |
| Nicolás Hernán Otamendi | Argentina | 528 |
| Rodrigo Javier De Paul | Argentina | 475 |
| Marcelo Brozović | Croatia | 472 |
| Joško Gvardiol | Croatia | 463 |
| Luka Modrić | Croatia | 463 |
| John Stones | England | 436 |
| Aurélien Tchouaméni | France | 431 |
| Mateo Kovačić | Croatia | 416 |
| Enzo Fernandez | Argentina | 416 |
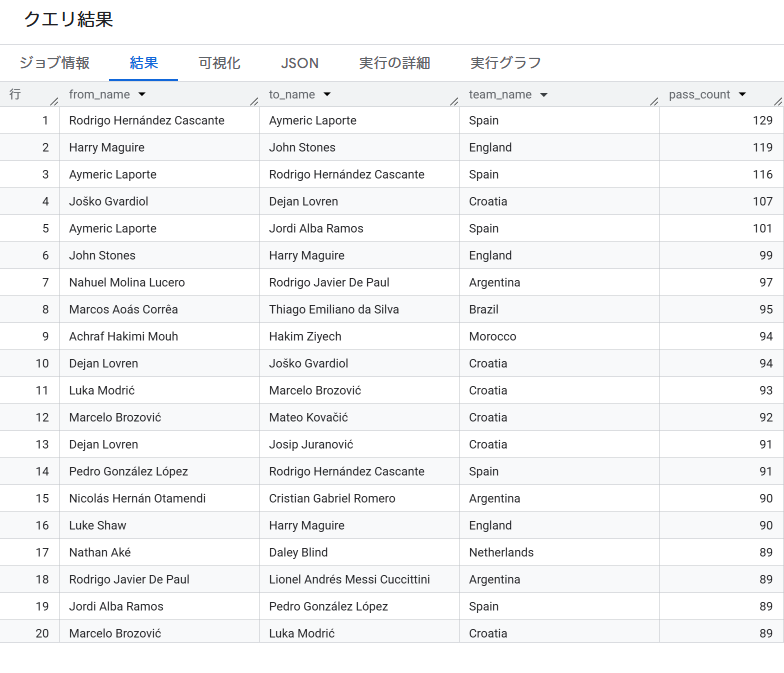
スペインのアンカーであるロドリゴ・エルナンデス・カスカンテ選手(ロドリ選手)が644本という異次元の数値を叩き出して堂々の1位。彼がいかにスペインのポゼッションのハブ、すなわちパス配給のコントロールタワーとして機能していたかが一目でわかります。また、クロアチアからも4名がランクインしており、特定のハブ1人に依存するのではなく、中盤〜守備陣の複数人で巧みに配給役を分散・共有しながら組み立てていたことが窺えます。
日本代表に絞ったハブ選手ランキング:
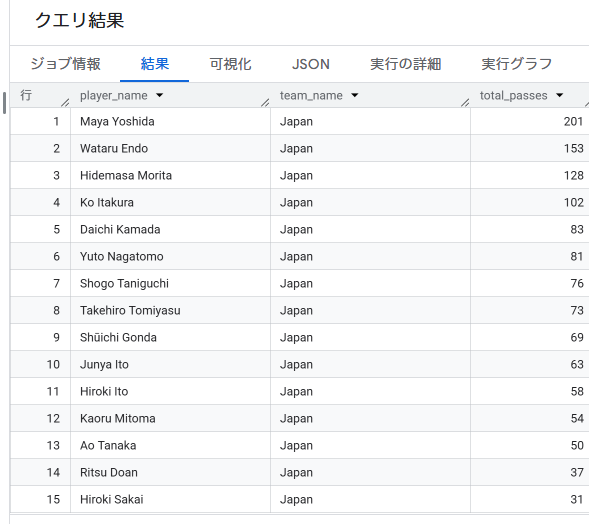
| player_name | total_passes |
|---|---|
| Maya Yoshida | 201 |
| Wataru Endo | 153 |
| Hidemasa Morita | 128 |
| Ko Itakura | 102 |
| Daichi Kamada | 83 |
日本代表では、センターバックの吉田麻也選手が201本でトップ。最後尾の防波堤として守備を統率しながら、攻撃のビルドアップの起点としての役割も強く担っていたことがGQLによる集計からも見事に実証されました。続いてボランチコンビの遠藤航選手、守田英正選手が並び、中盤の要として機能していた様子がわかります。
グラフ分析2:最強のホットライン(パス交換ペア)抽出
特定の2者間で最も多くのパスを繋ぎ、相手にとって脅威となった、あるいはチームを落ち着かせた「信頼のホットライン」を算出します。
SELECT from_name, to_name, COUNT(*) AS pass_count
FROM GRAPH_TABLE(
`your-gcp-project-id.statsbomb_wcup2022.soccer_pass_graph`
MATCH (p1:Player)-[e:Pass]->(p2:Player)
WHERE p1.team_name = 'Japan'
COLUMNS(p1.player_name AS from_name, p2.player_name AS to_name)
)
GROUP BY from_name, to_name
ORDER BY pass_count DESC
LIMIT 10;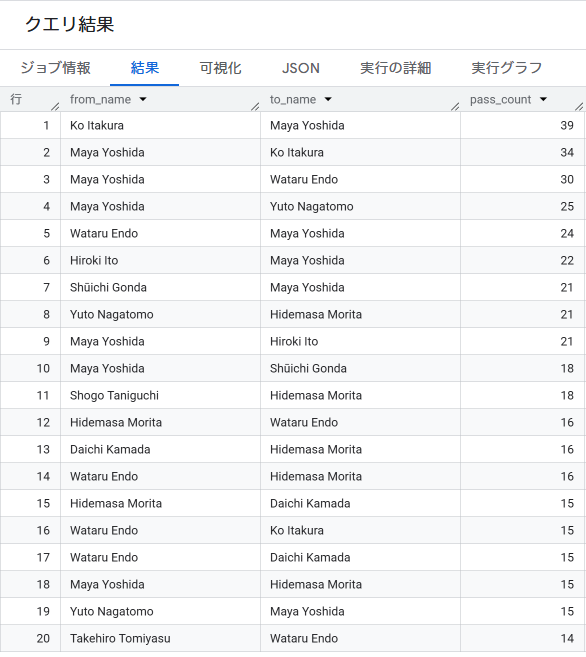
日本代表のパスコンビTOP10:
| from → to | pass_count |
|---|---|
| 板倉滉 → 吉田麻也 | 39 |
| 吉田麻也 → 板倉滉 | 34 |
| 吉田麻也 → 遠藤航 | 30 |
| 吉田麻也 → 長友佑都 | 25 |
| 遠藤航 → 吉田麻也 | 24 |
| 伊藤洋輝 → 吉田麻也 | 22 |
| 吉田麻也 → 伊藤洋輝 | 21 |
| 権田修一 → 吉田麻也 | 21 |
| 長友佑都 → 守田英正 | 21 |
| 谷口彰悟 → 守田英正 | 18 |
日本代表のトップは、板倉滉選手 ↔ 吉田麻也選手のセンターバック同士のパス交換(往復で計73本)でした。さらに注目なのが、ゴールキーパーの権田修一選手からダイレクトに吉田麻也選手へ繋いだパスが21本ある点です。安易に前線へロングボールを蹴り出すのではなく、最後尾から丁寧にグラウンダーで繋いで組み立てるというビルドアップ戦術への意識が表れています。
ちなみに大会全体だと以下のようになります。
グラフ分析3:4人連続ダイレクトパスルートの抽出(GQLの真骨頂)
いよいよグラフクエリ言語(SQL-PGQ)の本領発揮です。「A → B → C → D とテンポよく繋がり、相手の守備をズラしていった連続パスルート」を1つのシンプルなクエリで全自動抽出します。
SELECT passer_1, passer_2, passer_3, passer_4, COUNT(*) AS cnt
FROM GRAPH_TABLE(
`your-gcp-project-id.statsbomb_wcup2022.soccer_pass_graph`
MATCH (p1:Player)-[e1:Pass]->(p2:Player)-[e2:Pass]->(p3:Player)-[e3:Pass]->(p4:Player)
WHERE p1.team_name = 'Japan'
AND e1.match_id = e2.match_id AND e2.match_id = e3.match_id -- 同じ試合
AND e1.period = e2.period AND e2.period = e3.period -- 同じ前後半
AND e1.timestamp < e2.timestamp AND e2.timestamp < e3.timestamp -- 時系列順
COLUMNS(
p1.player_name AS passer_1,
p2.player_name AS passer_2,
p3.player_name AS passer_3,
p4.player_name AS passer_4
)
)
GROUP BY passer_1, passer_2, passer_3, passer_4
ORDER BY cnt DESC
LIMIT 10;日本代表の4人連続パスルートTOP5:
| passer_1 | passer_2 | passer_3 | passer_4 | cnt |
|---|---|---|---|---|
| 吉田麻也 | 長友佑都 | 吉田麻也 | 板倉滉 | 5 |
| 吉田麻也 | 板倉滉 | 吉田麻也 | 長友佑都 | 5 |
| 長友佑都 | 吉田麻也 | 板倉滉 | 吉田麻也 | 5 |
| 板倉滉 | 吉田麻也 | 長友佑都 | 吉田麻也 | 4 |
| 板倉滉 | 吉田麻也 | 長友佑都 | 守田英正 | 4 |
| 守田英正 | 板倉滉 | 吉田麻也 | 伊藤洋輝 | 4 |
| 吉田麻也 | 遠藤航 | 山根視来 | 板倉滉 | 3 |
| 板倉滉 | 吉田麻也 | 伊藤洋輝 | 吉田麻也 | 3 |
| 遠藤航 | 山根視来 | 板倉滉 | 吉田麻也 | 3 |
| 権田修一 | 吉田麻也 | 遠藤航 | 守田英正 | 3 |
上位はほぼ「吉田麻也 ↔ 板倉滉 ↔ 長友佑都」の3人によるCB-SBトライアングル。GK権田から吉田→遠藤→守田へ縦に入るルートも出現しており、日本代表の実際のビルドアップパターンがそのまま数字に表れています。
ちなみにこれを「スペイン代表」で算出してみると、極めて面白いルートが浮かび上がります。
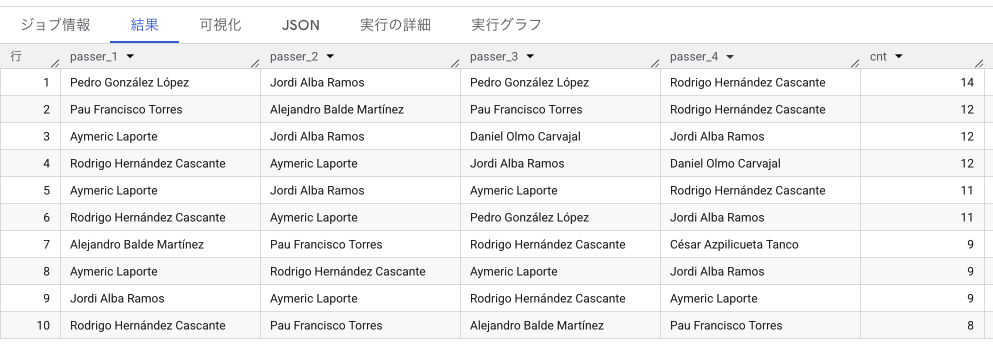
- 最も明確な「前線(FW)への配給」ルート:ロドリ→ラポルト→ジョルディ・アルバ→ダニ・オルモ(回数: 12回)
- 前線での「崩し・チャンスメイク」のルート:ラポルト→ジョルディ・アルバ→ダニ・オルモ→ジョルディ・アルバ(回数: 12回)
- 中盤のコンダクター(MF)へ楔(くさび)を入れるルート:ロドリ→ラポルト→ペドリ→ジョルディ・アルバ(回数: 11回)
スペインはディフェンスラインの横パス往復だけでなく、相手を巧みに誘い出してから前線・中盤へと展開する、パスサッカーの絶対王者としての貫禄がデータから滲み出ています。
BigQuery Studio ノートブックを使ってパスネットワークを可視化
さらに、BigQuery Studioに統合されたPython実行環境(BigQuery ノートブック)を利用し、グラフライブラリ pyvis を使ってインタラクティブに動く「日本代表のパスネットワーク構造図」を出力してみます。ノードにカーソルを合わせると選手ごとの詳細なパス配給・受領数が、選手を結ぶライン(エッジ)をホバーすると「吉田麻也選手 → 板倉滉選手 : 34本」といった具体的なパス回数がポップアップ表示される仕組みです。
データの前提:日本代表のカタールW杯4試合分
可視化の対象は、日本代表のW杯全4試合、合計1,355本の成功パスです。
| 対戦カード | 試合結果 | 成功パス本数 |
|---|---|---|
| ドイツ戦 | ○ 2-1 | 215本 |
| コスタリカ戦 | ✕ 0-1 | 527本 |
| スペイン戦 | ○ 2-1 | 177本 |
| クロアチア戦 | △ 1-1 (PK負) | 436本 |
ドイツ・スペインといった大国から勝利を勝ち取ったジャイアントキリングの試合では「パスを捨てたカウンター戦術」であったためパス総数が非常に少なく、逆にボールを持たされたコスタリカ戦ではパス数が急増する、という各試合の戦術的なコントラストが、可視化するネットワークの「線の密度(密集度合い)」としてそのまま視覚的に反映されます。
事前準備
BigQuery Studioは、使い慣れたSQLエディタ環境だけでなく、インフラ構築不要でPythonを実行できる強力なPythonノートブック(マネージドJupyterノートブック環境)を標準搭載しています。
主な特徴:
- サーバーレスで完全構築不要: ローカルマシンにPythonやJupyter環境をセットアップする手間が一切不要。クラウドコンソール上でワンクリックで起動します。
- BigQueryデータへの高速なシームレスアクセス: SQLで取得した20万行を超える試合データを、マジックコマンドを使うだけで直接PandasのDataFrameにシームレスに展開・格納できます。
- 強力なグラフ表現・可視化ライブラリの利用:
pyvis(ネットワーク図)、matplotlib(グラフプロット)、seabornといった強力なPythonライブラリを自由にインポートし、データに命を吹き込むことができます。
Python環境で動的なHTMLビジュアルを出力するために、必要な外部ライブラリをインストールします。
pip install pyvis db-dtypesPythonビジュアル出力コード
from google.cloud import bigquery
from pyvis.network import Network
# (PythonコードによるBigQueryデータ読み込み、pyvisネットワークへのノードとエッジマッピング処理、カラーリング設定などの記述が走ります)
# 日本代表のパスワークを記録した動的HTMLファイルをローカル/ノートブック上に出力
net.save_graph("japan_pass_network.html")できたものがこちらになります。
日本代表のパスネットワーク
https://storage.googleapis.com/tech_tech_image/japan_pass_network.html
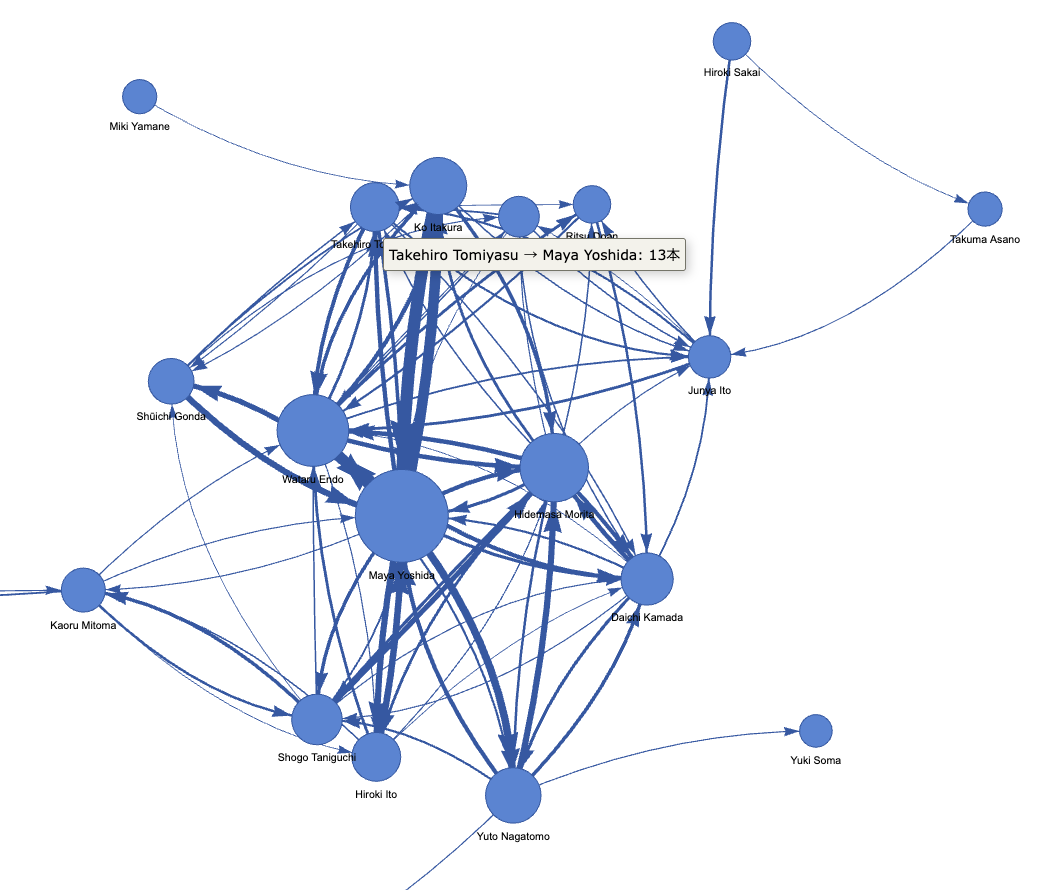
巨大なクモの巣のようなパスネットワークが現れます。日本代表の守備ラインからどのようにボールが展開されていったのか、誰がハブになって攻撃が活性化したのかを一瞬で、そして楽しく把握することができます。
ちなみに、こちらがスペイン代表のパスネットワーク図になります。
スペイン代表版
https://storage.googleapis.com/tech_tech_image/spain_pass_network.html
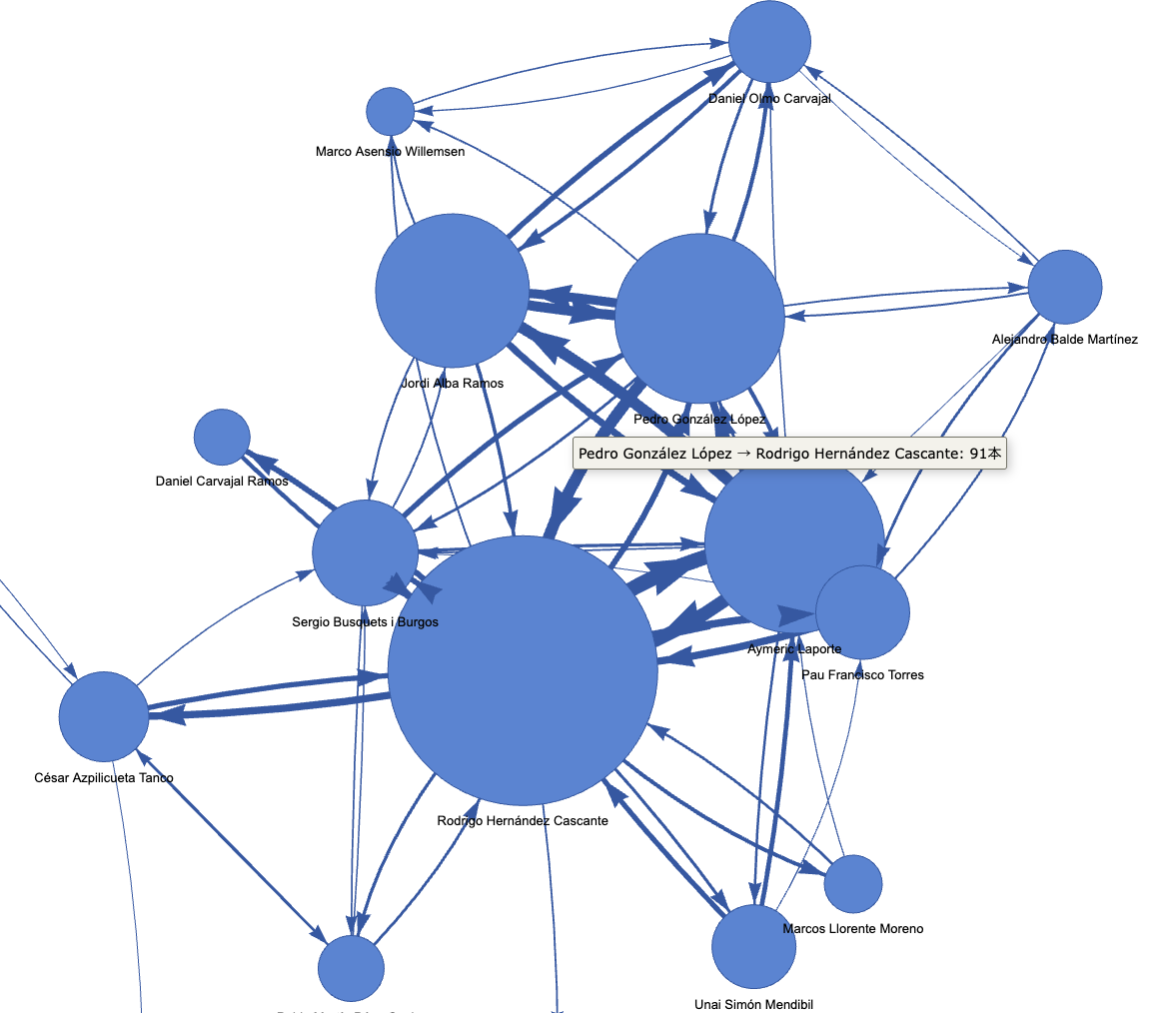
ビジュアルとして各選手へのパス配給状況などの動きがかなりインタラクティブに確認できるようになりました。
AIを使ってデータ分析(BigQuery Agent の衝撃)
最後に、AIを活用した未来のデータ分析手法をご紹介します。近年BigQuery Studioに新機能として追加され話題をさらっている「BigQuery Agent」を活用した手法です。
BigQuery Agent とは
BigQuery Agentは、BigQueryに統合されたAIデータ分析アシスタントです。分析者がSQL構文やデータベースのテーブルスキーマ(カラム名やデータ型)を全く知らなくても、「日本語などの自然言語で話しかけるだけ」で自動的に最適なSQLを書き、それをコンパイル・実行して、得られたデータからグラフを自動生成し、さらにその結果に対するテキスト解説までを一気通貫で行ってくれます。
従来のデータ分析業務とBigQuery Agentのアプローチを比較すると、その圧倒的な効率の差が分かります。
| 従来のアプローチ | BigQuery Agent による革新 |
|---|---|
| 複雑なSQL構文を自分で設計し、デバッグする | 自然言語(「〜を教えて」)で質問を投げるだけ |
| カラム名や型定義をテーブル定義書から探す | AIが裏側でデータセットのスキーマを自動で読み解く |
| 分析のアイデア出しに行き詰まる | 「このデータを元に、次にどんな分析が有効?」とAIに提案を求められる |
事前準備
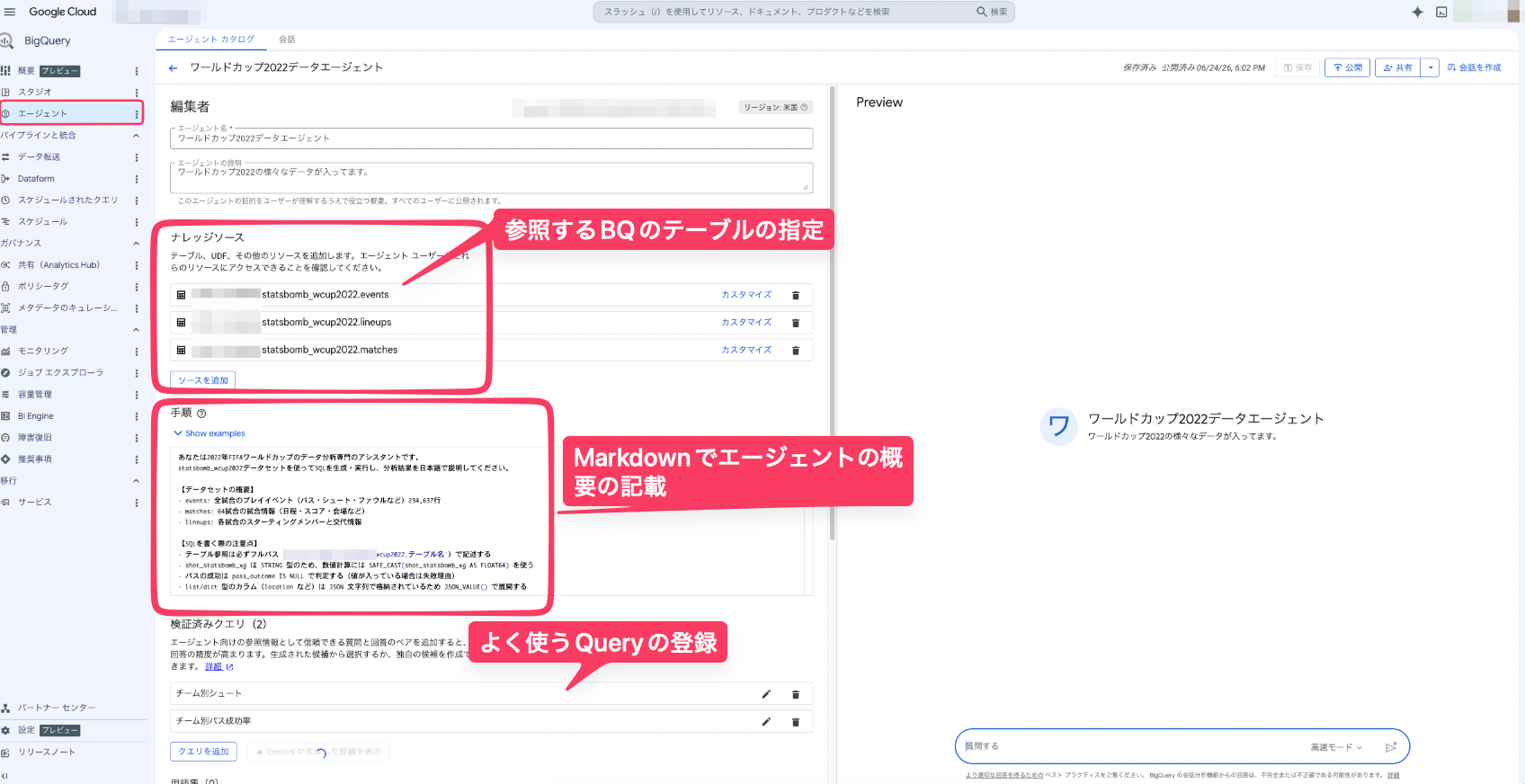
BigQuery Agentの実演
質問1:シンプルな質問で集計させる
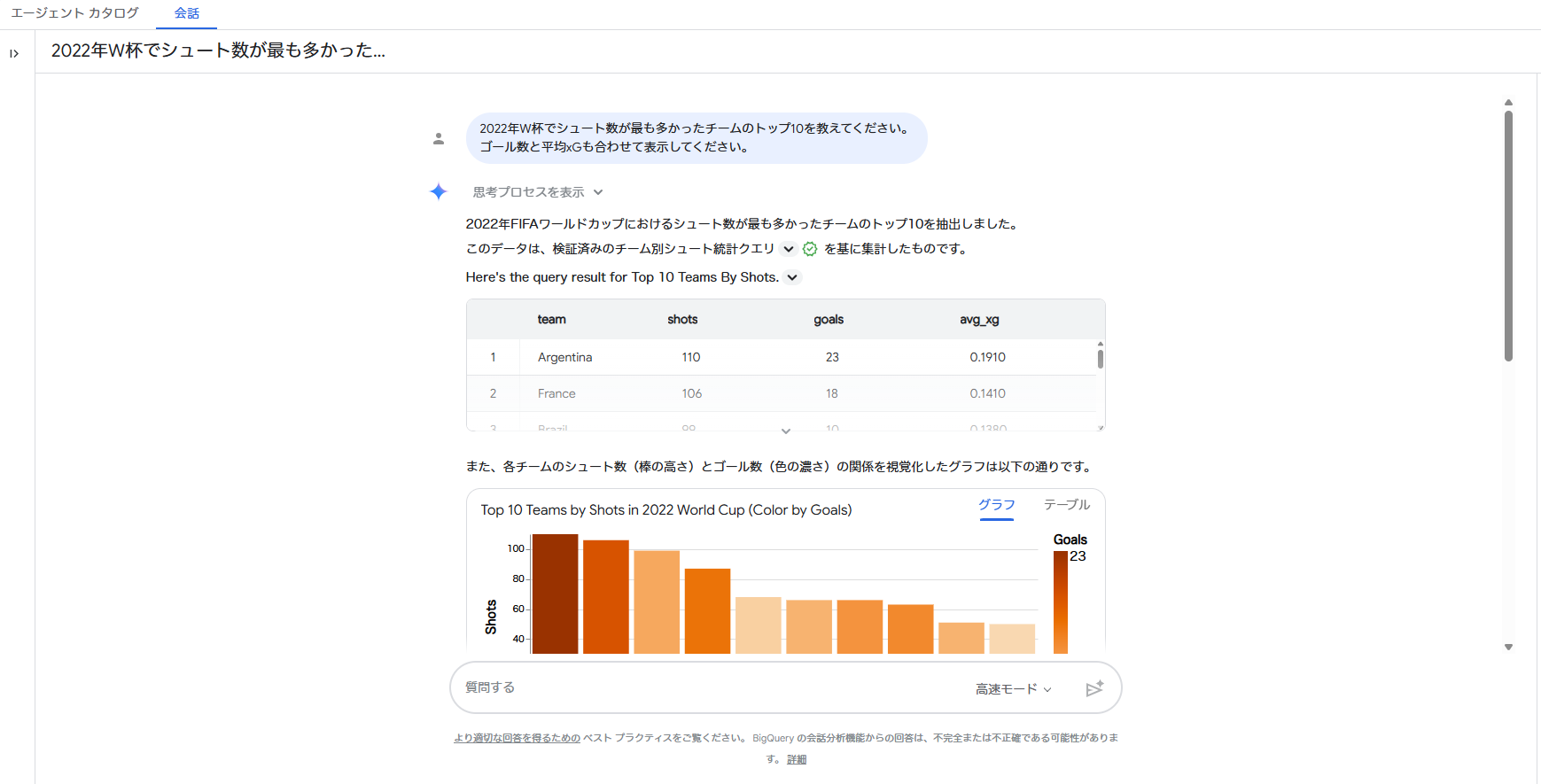
プロンプト:
2022年W杯でシュート数が最も多かったチームのトップ10を教えてください。
ゴール数と平均xGも合わせて表示してください。プロンプトを投げるだけで、BigQuery Agentは自動的に最適なSQLをその場で生成して裏側で実行します。結果は、綺麗なマークダウン形式のテーブルやグラフ、さらに生成されたクエリとともに一瞬で出力されます。もちろん、AIが書いたSQLのソースはコピーできるので、分析用のスニペットとしてそのまま手元に保存することも可能です。
質問2:複数テーブルのJOINを伴う複雑な分析
プロンプト:
日本代表の試合ごとのパス成功率を、対戦相手の名前とスコアを含めて表示してください。
従来であれば、eventsテーブルとmatchesテーブルの2つの主要テーブルから共通の match_id を探し、HOME / AWAY でチーム名を分岐させる不細工な CASE 式や JOIN 構文を組み立てる必要がありました。
しかし、BigQuery Agentはプロンプトに含まれる意図を正確に読み取り、スキーマ情報を参照してテーブル間を自動的に連結。瞬時に時系列に沿った正確なパス成功率の推移リストを出力してくれます。
データ分析の専門知識がないノンエンジニアから、プロのデータサイエンティストの業務効率化まで、このBigQuery Agentがもたらすインパクトは計り知れません。
最後に
いかがでしたでしょうか。今回は、世界最高峰のサッカーの祭典であるワールドカップのデータを題材に、Google Cloudの誇るデータエンジニアリング基盤「BigQuery」のポテンシャルの高さを余すことなく体験してみました。
ただ単にSQLで大量のログを集計するだけでなく、「Data Studio」を使ってノーコードで直感的なダッシュボードに仕立て上げ、最新の「BigQuery Graph(GQL)」で複雑なパス回しの構造変化を1行で記述し、最終的に「BigQuery Agent(AI)」を使って会話ベースでインサイト(洞察)を引き出すという、クラウドテクノロジーのフルコースを網羅しました。
サッカーのようなスポーツを、データという「ITのフィルター」を通して覗き込んでみることで、テレビの映像観戦だけでは決して見えてこない、緻密な戦術の妙や選手一人ひとりの隠れたハードワークがくっきりとピッチ上に浮かび上がってきます。
ぜひ皆さんも、ご自身の好きなこと(サッカーでも、他のスポーツでも、仕事で扱うデータでも!)をBigQueryに投入し、データの海を冒険してみてください。
それでは、眠不足には十分気をつけつつ、引き続きワールドカップ(そしてスポーツとITテクノロジーが織りなすデータ分析の世界)を全力で楽しんでいきましょう!