

【Google Cloud】本番影響を最小限に!バックアップから作る使い捨てCloud SQL → BigQuery連携基盤
はじめに
こんにちは。エヌデーデーの金子です。
皆様、データ分析基盤としてのBigQuery活用はバッチリでしょうか。
ビジネスワークロードを処理するCloud SQLに蓄積したデータをBigQueryに保管し、分析を始めたいという要望は非常にメジャーなものですよね。
Cloud SQLからBigQueryへのデータ転送は様々な方法が用意されています。
しかし、業務上の処理が昼夜問わず走り続ける本番ワークロードにおいて、安全性を担保しながらデータ転送を導入するのは中々ハードルが高いケースもあるかと思います。
本記事では本番ワークロードへの影響を最大限抑えたうえで、定期的なCloud SQL→BigQueryへの柔軟かつ自動化可能なデータ転送手順をご紹介します。
本記事で想定する読者様
- Cloud SQLのデータを、日次・月次など定期的にBigQueryへ転送することをご検討中の方
- リアルタイムでのデータ転送は本記事では言及しないので、ご了承ください。
- 本番環境への影響を最小限に抑えつつ、BigQueryによるデータ分析の導入効果を検証したい方
ソリューション概要
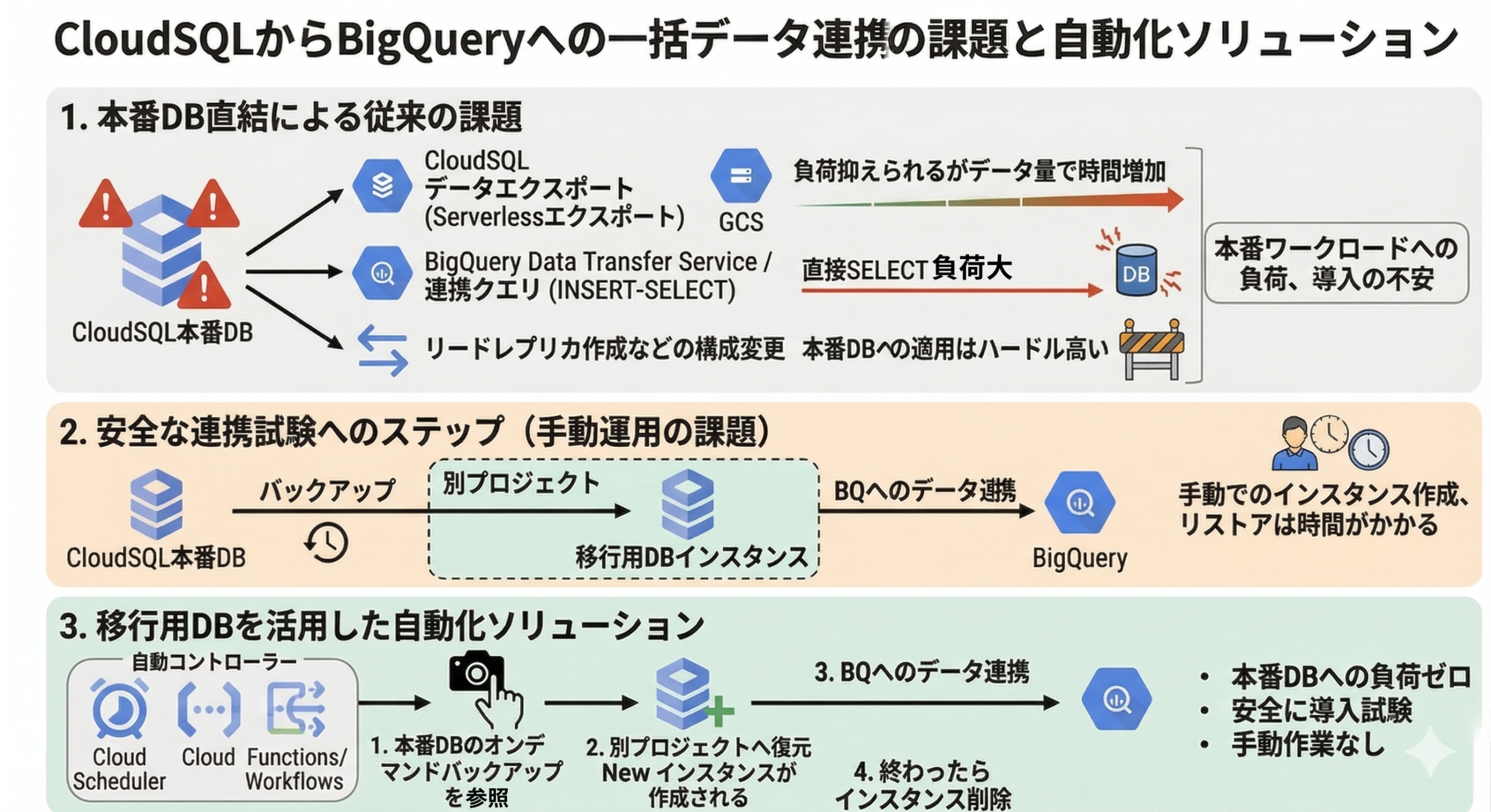
Cloud SQL→BigQueryへの一括データ転送アプローチ
Cloud SQLからBigQueryへの一括データ連携を行う場合、代表的な手法として主に以下の3つが挙げられます。
- BigQuery Data Transfer Service(DTS)の利用
- BigQueryの連携クエリ(Federated Queries)を利用した
INSERT-SELECT - Cloud SQLのエクスポート機能でGCSに出力し、BigQueryへロード
これらは非常に便利な機能ですが、実際の本番データベースから直接データを抽出するため、少なからずDB側に負荷がかかるという課題があります。移行するデータ量が多い場合、様々な業務処理が昼夜問わず走る本番環境へいきなり導入するのは、運用リスクの観点から少し怖いと感じる方も多いのではないでしょうか。
負荷軽減の策として、公式ドキュメントでも推奨されているサーバーレスエクスポートを利用してパフォーマンスへの影響を分離する方法もあります。
しかし、データエクスポート処理自体が抽出データ量に比例して処理時間が伸びやすい傾向にあります。
また、SELECTの負荷をオフロードするためにリードレプリカを構築するといった構成変更も、本番データベースに対しては手軽に適用しがたいケースがあるでしょう。
本番に影響を与えず、安全かつ手軽にデータ転送を行う
本番ワークロードへの影響を最小限に抑え、安全にデータ連携の検証や導入を行うためには、「本番DBのバックアップを別プロジェクトのインスタンスに復元(リストア)し、そこから移行作業を行う」のが、最も現実的で納得感のあるアプローチではないでしょうか。
Cloud SQLを使っている場合自動バックアップを取っているケースは多いでしょうし、断面としてオンデマンドバックアップを取得する場合も、クエリで抽出するよりはるかに負荷が少なく高速です。
しかし、この構成にも弱点があります。
別プロジェクトへのインスタンス作成、バックアップのリストア、データ抽出、そして不要になったリソースの削除といった一連の作業を手運用で行うと、運用コストや作業時間が大きく膨らんでしまいます。
そこで本記事では、この手作業による課題を解決するため、Google Cloud Workflowsを用いてフル自動化するソリューションをご紹介します。
処理構成
実際の処理を組んでみましょう。
この処理の前提として、分析用プロジェクトは以下の設定がされている必要があります。
- 分析用プロジェクトの作成
- BigQueryデータセットと連携先テーブルの作成
- 分析用プロジェクトにVPCとCloud SQL用のプライベートサービスアクセス(PSA)が設定済みであること
(前提:分析対象となる本番Cloud SQLのオンデマンドバックアップが取られている)
- 最新の復元元バックアップIDを取得する
- 復元先インスタンスを新規作成
- バックアップを復元先インスタンスにリストア
- BigQuery連携用クエリをキック
- 復元先インスタンスを削除
- 失敗・成功通知をWebhook呼び出し
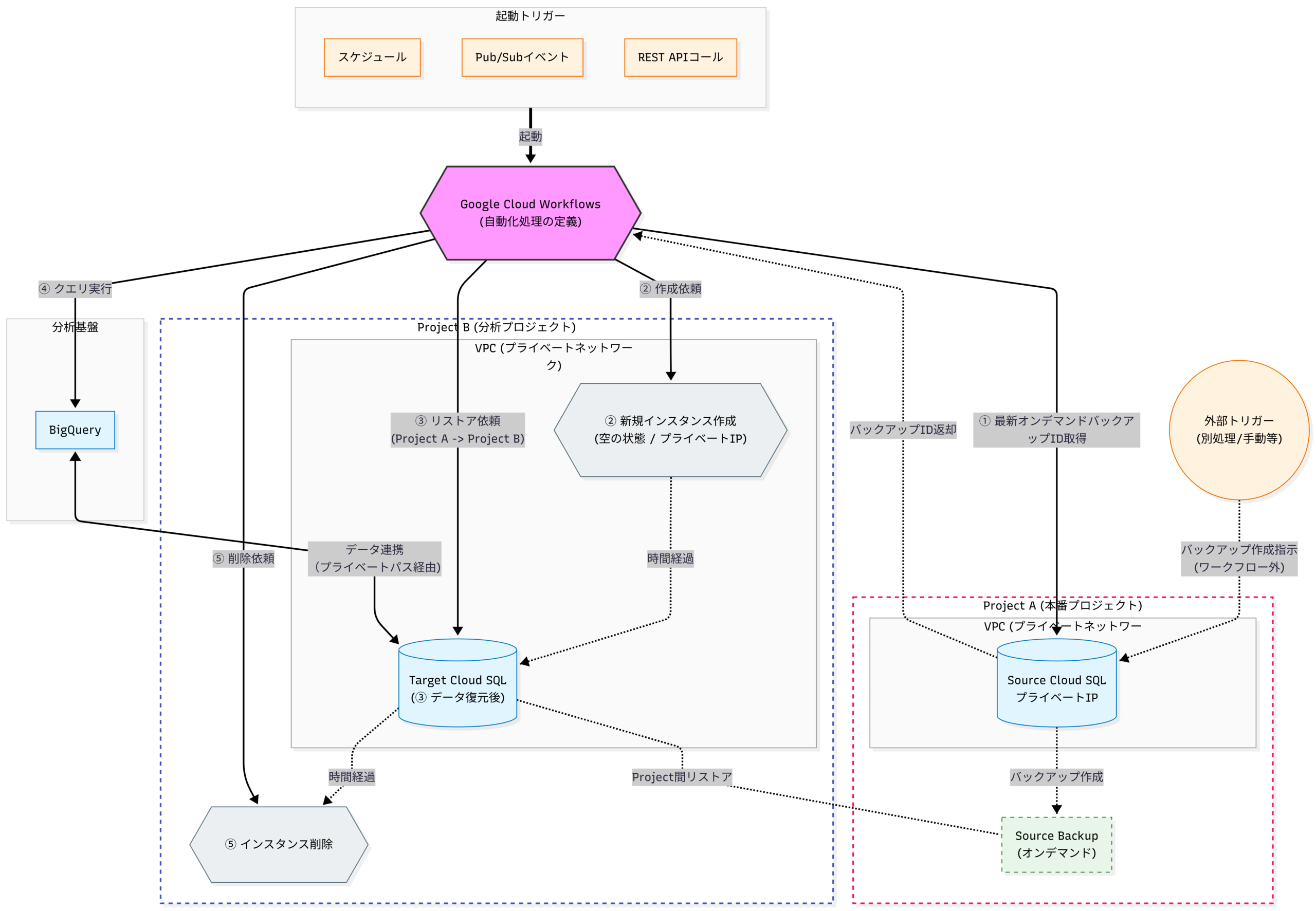
この処理の安全・便利なポイントは以下です。
- 本番プロジェクトに一切の影響を与えない
- 分析チームと本番運用チームでプロジェクトレベルでのIAM権限境界の明瞭運用が可能
- 分析用Cloud SQLインスタンスの一時インスタンス化によるコスト削減
- 分析プロジェクトにおいてもCloud SQLおよびBigQueryからCloud SQLへの問い合わせがプライベート
- 中間ファイル/リソースを経由しない、シンプルなCloud SQL→BigQueryのデータ連携経路の安全性
- 連携クエリ内で、Cloud SQLのデータをSQLを用いて柔軟に加工可能。
また、同時に注意点も以下に記します。
- 分析用Cloud SQLインスタンスのストレージは、復元するバックアップサイズ以上でなければならない。また、データベースエンジンの種類とバージョンは一致していなければならない。
- 新しいインスタンスに復元するための要件(日本語版)と新しいインスタンスに復元するための要件(英語版)でストレージ容量についての表記が異なります。英語版では「
storageAutoResizeの設定が本番DBにされていれば、バックアップもその設定を引き継ぎ、リストア時に自動的にストレージ容量が増加する。レガシーインスタンスではこの機能は有効になっていない。」とあります。原則は本番DB以上の容量を確保するで良いかと思いますが、ストレージ自動追加オプションが本番DBになされていれば、リストア先のインスタンスを最小容量で作成しても、リストア時に自動拡張されることは確認しました。
- 新しいインスタンスに復元するための要件(日本語版)と新しいインスタンスに復元するための要件(英語版)でストレージ容量についての表記が異なります。英語版では「
- バックアップのリストアであるため、分析用Cloud SQLインスタンスの接続には本番用インスタンスのユーザ/パスワードが必要になる。
- 連携クエリの作成や実行のテストは、接続するインスタンスが存在していないとエラーとなる。
- 連携クエリの制限事項の都合上、BigQueryデータセットと分析用Cloud SQLインスタンスのリージョンは互換性がなければならない。
- BigQuery:
asia-northeast1Cloud SQL:asia-northeast1OK - BigQuery:
USマルチリージョンCloud SQL:us-central1OK(※1日1TBまで) - BigQuery:
USマルチリージョンasia-northeast1NG
- BigQuery:
自動化手順
では順に自動化の手順を記載します。
シークレットを管理
最初に、Cloud SQL接続情報と通知先WebhookURLを分析用プロジェクトのSecret Managerでシークレット管理します。
本番DBバックアップをリストアするため、分析用Cloud SQLインスタンスには本番同様のDBユーザとパスワードで接続する必要があります。
※この接続情報を本番プロジェクトで管理している/したい場合は、作成不要です。
WebhookURLはWorkflowsからSlackやGoogle Chatへの通知を行うための接続URLです。本自動化ではGoogle Chatの限定公開スペースへの通知を想定します。
※これをGoogleCloudの通知チャネルで行い、ログベースアラートで発報する場合は作成不要です。WebhookURL通知ではなく、Workflows内でログ書き込みを行う実装に適宜修正してください。
連携クエリを作成
連携クエリを作成するには、接続先のインスタンスが起動している必要があるので、まず分析用Cloud SQLインスタンスを一時的に立てます。
Cloud SQL接続設定を参照し、BigQueryからCloud SQLへの接続設定を作ります。
この際、Cloud SQLの接続設定の「プライベートパスを有効にする」にチェックを入れることで、BigQuery – Cloud SQL間の通信が内部直接パス参照となります。
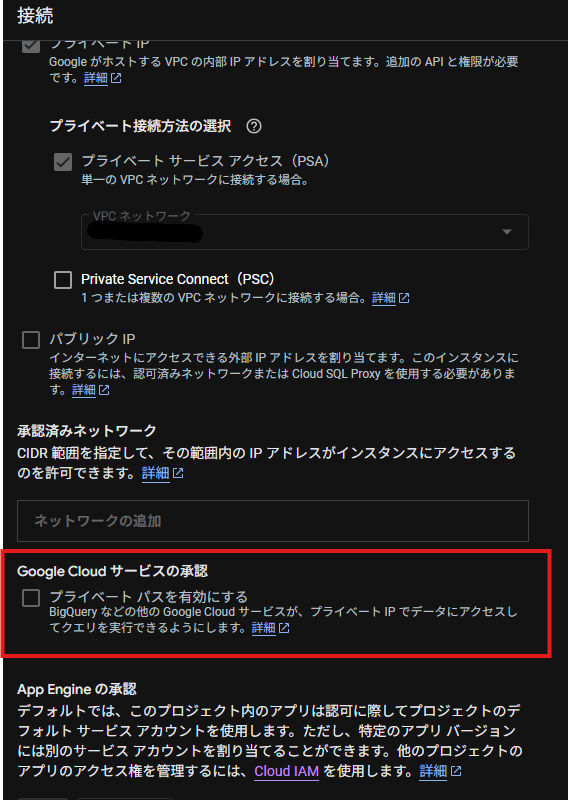
外部接続を作成すると、裏でその接続が使用するサービスアカウントがservice-PROJECTNUMBER@gcp-sa-bigqueryconnection.iam.gserviceaccount.comの形式で自動で払い出されます。
このサービスアカウントにCloudSQLクライアント(roles/cloudsql.client)を割り当てます。
接続設定が完了したら、EXTERNAL_QUERY構文でクエリを開発します。
完了したらストアドにまとめておき、後述するWorkflowsから呼び出しやすくします。
INSERT INTO `YOUR_PROJECT.YOUR_DATASET.YOUR_TABLE`
SELECT column1, column2, ...
FROM EXTERNAL_QUERY(
'projects/YOUR_PROJECT/locations/YOUR_REGION/connections/YOUR_CLOUDSQL_INSTANCE',
'''SELECT * FROM YOUR_CLOUDSQL_TABLE;'''
);Workflows用のサービスアカウントを作成
Workflowsを作成する準備として、実行用サービスアカウントを作成してIAMを付与します。
IAMは以下のように付与していきます。
- バックアップを参照する本番プロジェクトに付与
- roles/cloudsql.viewer
- 分析用プロジェクトに付与
- roles/bigquery.jobUser
- roles/bigquery.connectionUser
- roles/bigquery.dataEditor(BQ内データ編集実行)
- roles/secretmanager.secretAccessor(DB接続情報・WebhookURLの取得。DB接続情報が本番プロジェクトのシークレットに保存されている場合、本番プロジェクトに対して付与する。)
- roles/cloudsql.admin(インスタンスの作成・リストア・接続・読み取り・削除)
Workflowsを作成
前段で準備したサービスアカウントをアタッチし、以下のソースを使います。
変数は参考値なので、適宜修正してください。
main:
params: [args]
steps:
# ---------------------------------------------------------
# 0. 変数定義
# ---------------------------------------------------------
- init_variables:
assign:
- src_project: "YOUR_SOURCE_PROJECT" # 本番プロジェクト
- src_instance: "YOUR_SOURCE_CLOUDSQL_INSTANCE"# 本番プロジェクト
- dst_project: "YOUR_TARGET_PROJECT" # 分析用プロジェクト
- dst_instance: "YOUR_TARGET_CLOUDSQL_INSTANCE" # 分析用プロジェクト
- dst_region: "YOUR_TARGET_REGION" # 分析用プロジェクト
- network_id: ${"projects/" + dst_project + "/global/networks/YOUR_TARGET_PROJECT_VPC"} # 分析用プロジェクトのVPC
- psa_range_name: "YOUR_TARGET_PSA_IP_RANGE_NAME" # 分析用Cloud SQLのプライベートサービスアクセス設定
- secret_name: "projects/YOUR_PROJECT_NUMBER/secrets/YOUR_SECRET_NAME/versions/latest"
- webhook_secret_name: "projects/YOUR_PROJECT_NUMBER/secrets/YOUR_SECRET_NAME/versions/latest"
- db_tier: "db-custom-2-7680" # 2コア 7.5GB
- db_engine: "POSTGRES_15" # DBエンジンは復元元と合わせる
- data_disk_size_gb: "600" # バックアップサイズに合わせる。本番プロジェクトのCloud SQLに自動拡張オプションが設定されていれば、リストア時にストレージ容量が自動拡張する。
- bq_stored_proc: "CALL `YOUR_PROJECT.YOUR_DATASET.YOUR_PROCEDURE`()" # 連携クエリをストアド化してコール
# ---------------------------------------------------------
# 1. Secret Manager取得
# ---------------------------------------------------------
- get_db_password:
call: googleapis.secretmanager.v1.projects.secrets.versions.access
args:
name: ${secret_name}
result: secret_response
- decode_secret:
assign:
- db_password: ${text.decode(base64.decode(secret_response.payload.data))}
- get_webhook_url:
call: googleapis.secretmanager.v1.projects.secrets.versions.access
args:
name: ${webhook_secret_name}
result: webhook_res
- decode_webhook_url:
assign:
- webhook_url: ${text.decode(base64.decode(webhook_res.payload.data))}
# ---------------------------------------------------------
# 2. メイン処理(Try-Except)
# ---------------------------------------------------------
- workflow_execution:
try:
steps:
- get_backup_runs:
call: http.get
args:
url: ${"https://sqladmin.googleapis.com/v1/projects/" + src_project + "/instances/" + src_instance + "/backupRuns"}
auth:
type: OAuth2
result: backups_response
- find_latest_ondemand_backup:
assign:
- latest_backup_id: null
- idx: 0
- loop_check_backup:
switch:
- condition: '${idx >= len(backups_response.body.items)}'
next: check_backup_found
- condition: '${backups_response.body.items[idx].type == "ON_DEMAND" and backups_response.body.items[idx].status == "SUCCESSFUL"}'
assign:
- latest_backup_id: ${backups_response.body.items[idx].id}
next: check_backup_found
next: increment_idx
- increment_idx:
assign:
- idx: ${idx + 1}
next: loop_check_backup
- check_backup_found:
switch:
- condition: '${latest_backup_id == null}'
next: raise_backup_error
next: create_instance
- raise_backup_error:
raise: "No successful on-demand backup found."
- create_instance:
call: http.post
args:
url: ${"https://sqladmin.googleapis.com/v1/projects/" + dst_project + "/instances"}
auth:
type: OAuth2
body:
name: ${dst_instance}
region: ${dst_region}
databaseVersion: ${db_engine}
rootPassword: ${db_password}
settings:
tier: ${db_tier}
dataDiskSizeGb: ${data_disk_size_gb}
storageAutoResize: true
ipConfiguration:
ipv4Enabled: false
privateNetwork: ${network_id}
allocatedIpRange: ${psa_range_name}
enablePrivatePathForGoogleCloudServices: true
backupConfiguration:
enabled: false
deletionProtectionEnabled: false
result: create_op
- wait_for_create_instance:
call: wait_for_operation
args:
operation_url: ${create_op.body.selfLink}
- restore_backup:
call: http.post
args:
url: ${"https://sqladmin.googleapis.com/v1/projects/" + dst_project + "/instances/" + dst_instance + "/restoreBackup"}
auth:
type: OAuth2
body:
restoreBackupContext:
backupRunId: ${latest_backup_id}
project: ${src_project}
instanceId: ${src_instance}
result: restore_op
- wait_for_restore_backup:
call: wait_for_operation
args:
operation_url: ${restore_op.body.selfLink}
- run_bq_stored_proc:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/" + dst_project + "/queries"}
auth:
type: OAuth2
body:
query: ${bq_stored_proc}
useLegacySql: false
location: ${dst_region}
result: bq_job
- wait_for_bq:
call: http.get
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/" + dst_project + "/jobs/" + bq_job.body.jobReference.jobId}
query:
location: ${bq_job.body.jobReference.location}
auth:
type: OAuth2
result: bq_status
- check_bq_status:
switch:
- condition: '${bq_status.body.status.state != "DONE"}'
next: sleep_and_check_bq
- condition: '${"errorResult" in bq_status.body.status}'
next: raise_bq_error
next: delete_instance
- raise_bq_error:
raise: ${bq_status.body.status.errorResult.message}
- sleep_and_check_bq:
call: sys.sleep
args:
seconds: 30
next: wait_for_bq
- delete_instance:
call: http.delete
args:
url: ${"https://sqladmin.googleapis.com/v1/projects/" + dst_project + "/instances/" + dst_instance}
auth:
type: OAuth2
- notify_success:
call: send_notification
args:
url: ${webhook_url}
status: "SUCCESS"
message: "Cloud SQL復元とBigQuery連携が正常に完了しました。インスタンスを削除しました。"
except:
as: e
steps:
- notify_failure:
call: send_notification
args:
url: ${webhook_url}
status: "FAILURE"
message: '${"Cloud SQL復元とBigQuery連携時にエラーが発生しました。内容: " + e.message}'
- raise_error:
raise: ${e}
- final_result:
return: "Workflow finished."
# =========================================================
# サブワークフロー
# =========================================================
send_notification:
params: [url, status, message]
steps:
- post_to_webhook:
call: http.post
args:
url: ${url}
body:
text: '${"[" + status + "] Cloud SQL Restore Workflow\n" + message}'
result: notification_res
- return_res:
return: ${notification_res}
wait_for_operation:
params: [operation_url]
steps:
- sleep:
call: sys.sleep
args:
seconds: 30
- get_status:
call: http.get
args:
url: ${operation_url}
auth:
type: OAuth2
result: op_response
- check_status:
switch:
- condition: '${op_response.body.status == "DONE"}'
next: check_error
next: sleep
- check_error:
switch:
- condition: '${"error" in op_response.body}'
next: raise_op_error
next: return_success
- raise_op_error:
raise: ${op_response.body.error}
- return_success:
return: true処理解説
まず本番プロジェクトの最新のオンデマンドバックアップIDを取得します。
ここは「descriptionが○○」や自動/オンデマンドなど、フィルターのカスタムが可能です。
- get_backup_runs:
call: http.get
args:
url: ${"https://sqladmin.googleapis.com/v1/projects/" + src_project + "/instances/" + src_instance + "/backupRuns"}
auth:
type: OAuth2
result: backups_response
- find_latest_ondemand_backup:
assign:
- latest_backup_id: null
- idx: 0
- check_backup_found:
switch:
- condition: '${latest_backup_id == null}'
next: raise_backup_error
next: create_instance
- raise_backup_error:
raise: "No successful on-demand backup found."分析用Cloud SQLインスタンス作成⇒バックアップID指定でリストアを行っています。
インスタンス作成とリストアは時間がかかる処理なので、30秒ごとに結果をポーリングします。
- create_instance:
call: http.post
args:
url: ${"https://sqladmin.googleapis.com/v1/projects/" + dst_project + "/instances"}
auth:
type: OAuth2
body:
name: ${dst_instance}
region: ${dst_region}
databaseVersion: ${db_engine}
rootPassword: ${db_password}
settings:
tier: ${db_tier}
dataDiskSizeGb: ${data_disk_size_gb}
storageAutoResize: true
ipConfiguration:
ipv4Enabled: false
privateNetwork: ${network_id}
allocatedIpRange: ${psa_range_name}
enablePrivatePathForGoogleCloudServices: true
backupConfiguration:
enabled: false
deletionProtectionEnabled: false
result: create_op
- wait_for_create_instance:
call: wait_for_operation
args:
operation_url: ${create_op.body.selfLink}
- restore_backup:
call: http.post
args:
url: ${"https://sqladmin.googleapis.com/v1/projects/" + dst_project + "/instances/" + dst_instance + "/restoreBackup"}
auth:
type: OAuth2
body:
restoreBackupContext:
backupRunId: ${latest_backup_id}
project: ${src_project}
instanceId: ${src_instance}
result: restore_op
- wait_for_restore_backup:
call: wait_for_operation
args:
operation_url: ${restore_op.body.selfLink}BigQueryのストアドプロシージャを実行し、データ連携を行います。
クエリ処理なのでデータ量に比例して処理時間が長くなります。これも30秒ずつポーリングして結果を待機します。
- run_bq_stored_proc:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/" + dst_project + "/queries"}
auth:
type: OAuth2
body:
query: ${bq_stored_proc}
useLegacySql: false
location: ${dst_region}
result: bq_job
- wait_for_bq:
call: http.get
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/" + dst_project + "/jobs/" + bq_job.body.jobReference.jobId}
query:
location: ${bq_job.body.jobReference.location}
auth:
type: OAuth2
result: bq_status
- check_bq_status:
switch:
- condition: '${bq_status.body.status.state != "DONE"}'
next: sleep_and_check_bq
- condition: '${"errorResult" in bq_status.body.status}'
next: raise_bq_error
next: delete_instance
- raise_bq_error:
raise: ${bq_status.body.status.errorResult.message}
- sleep_and_check_bq:
call: sys.sleep
args:
seconds: 30
next: wait_for_bq連携クエリ処理が完了したら、Cloud SQLインスタンスを削除し、成功通知を発報します。
※連携クエリの開発や検証が完了するまでは、Cloud SQLインスタンスの削除はコメントアウトしておくと結果検証がスムーズです。
- delete_instance:
call: http.delete
args:
url: ${"https://sqladmin.googleapis.com/v1/projects/" + dst_project + "/instances/" + dst_instance}
auth:
type: OAuth2
- notify_success:
call: send_notification
args:
url: ${webhook_url}
status: "SUCCESS"
message: "Cloud SQL復元とBigQuery連携が正常に完了しました。インスタンスを削除しました。"おわりに
いかがでしたでしょうか。
このようなステップを踏むことで、BigQuery – Cloud SQL間のデータ転送を本番環境への影響を限りなく抑えたうえで実現することができます。
一時的なインスタンスを活用することで、不要な待機コストも削減できるのがこのアーキテクチャの強みです。一連の作業をWorkflowsでコード化しているため、ヒューマンエラーが入り込む余地もありません。
あとはこのWorkflowsをCloud Schedulerで定期実行したり、API呼び出しで任意のタイミングで実行するよう設定すれば、安全で手放しに運用できるデータ転送パイプラインの完成です。
本番データベースの負荷や設定変更を理由にBigQueryでの分析をためらっていた方の、課題解決のヒントになれば幸いです。