

GCP を使って名刺管理ボットを本気で作ってみた
はじめに
かなり前から名刺管理アプリが欲しく各種サービスの資料を集めては選考していたのですがどのサービスも料金が高く、又、オーバースペックでした。無料のサービスもありますが根拠のない不安の下、何となく気が乗りませんでした。それでも周期的に名刺管理 アプリ の必要を感じ情報収集をしていたある日、どうせなら自分で作ってしまった方が格安で欲しい機能のものが手に入るのではないかと考えました。
昨今はクラウドを利用することで OCR などが高額なソフトウェアを購入しなくても使用できます。それらを活用すれば自分が欲しい程度の機能なら実現できそうだと考えました。
という事で、今回は Google Cloud Platform(GCP)の自然言語処理等の各種サービスを使って本気で名刺管理アプリを作ってみました。結果としては十分実用に耐えられるものが出来たと思いますし、実際に私も 2,000 枚強の名刺を登録して不便はありません。
とは言え、実用化を目指してアプリを作成し始めるとやはり何かしらの課題が発生して何かしらの工夫や対応に追われることになりました。今回はその実用化に向けて苦労や工夫した点に焦点を当ててポイントを紹介したいと思います。
また、当社は Office 365 を導入しているためコミュニケーションツールとして Microsoft Teams(Teams) を活用しています。そこで今回の名刺管理アプリは Teams のボットとして名刺管理機能を提供することにしました。
当記事では、Teams 用の管理ボットを GCP をバックエンドとして作る上での、技術的なポイントについて紹介します。
ゴール
- 名刺管理ボットを作る為に使用したアーキテクチャが分かる
- 名刺管理ボットを実装する為のポイントが分かる
- 実際に使えるものにする為にどの様な課題があり、どの様な工夫が必要だったかが分かる
初めまして メェ氏 です

先ずは簡単に作成した名刺管理ボットの紹介をします。
ボットの名前は「メェ氏」です。Teams アプリ上で、名刺の登録や検索、修正、削除等を行ってくれます。有料の名刺管理サービスには劣りますが、名刺を紙で保管して、必要になったときに名刺の束を掘り起こすのに比べたらよほど楽です。
普通、名刺は紙で保存していると思いますが、この名刺管理ボットは Teams のアプリ上で動くので、出先で名刺を見たくなった時やテレワークで自宅で名刺を見たくなった時にもスマホ等で直ぐに名刺を確認できます。
逆に言うと出来る事はそれだけで、それを如何に GCP のアーキテクチャを使用して使えるレベルで実現するかというのがテーマでした。
使用した主なアーキテクチャは次の通りです。言語ランタイムは Node.js 8 を使用しています。
| チャットボットアプリ | Azure Bot Service Web App Bot(Web App Bot) |
| ボットエンジン(自然言語処理) | Google Cloud Dialogflow(Dialogflow) |
| 名刺情報読み込み(OCR) | Google Cloud Vision API (Vision API) |
| 名刺管理アプリ(Webhook) | Google Cloud Functions(Cloud Functions) |
| 名刺画像保存 | Google Cloud Storage(Cloud Storage) |
| 検索エンジン(全文検索) | Elasticsearch |
なお、これらは開発初期の構成で最終的にチャットボットアプリと名刺管理アプリは Google Kubernetes Engine 上へ移行しました。理由はレスポンスを改善する為です。その詳細や移行方法等は後述します。
メェ氏で名刺を検索する場合は以下の図の様な操作になります。

基本的にスマホで撮影した名刺画像を検索するボットアプリですが、使い勝手を良くするために色々な機能を実装しています。
単純な検索では同じ人の名刺は最新のものしか表示しませんが過去の名刺を表示することも出来ます。また、他者が登録した名刺を見る機能や自分が直近で登録した名刺を確認する機能、他者が自分が登録した人と同じ人の名刺を登録するとその旨を通知する機能等、そこそこ作り込んでいます。
この辺りの機能の作り込みはアプリの作り込み加減次第なので技術的なハードルはさほどありません。問題となるのは Vision API による OCR の精度となります。もしこれが人間と同程度の精度で文字を認識してくれれば何の苦労も無いのですが、やはり期待通りに動いてはくれませんでした。
それに対してどう対処したかが当記事の本題です。
システム構成概要
システム構成概要は次の図の通りです。社内からスキャナを使って一括登録の機能も作成していますが、これは通常の Web アプリケーションですので今回は特に説明しません。当記事では名刺管理ボット部分に注目して説明します。
名刺管理ボットは Teams からのメッセージを Azure の Web App Bot を経由して GCP の Dialogflow へ渡します。この Dialogflow が起点となって 各種受け答えを行ったり Cloud Functions に実装された名刺管理処理を実行します。Web App Bot 側には名刺管理の為のロジックは極力実装しないようにしました。これにより Teams ではない他のチャットアプリに名刺管理ボットを移行する際に簡単に行えるようになります。実際に、技術検証として途中まで Teams と並行して Slack 版も作成していました。
Azure を経由させているのは Office365 のリソースにアクセスしたい為です。後述しますが、この Web App Bot の処理は最終的に GKE 上へ移行した為、Azure 側はボットチャンネル登録(Bot Channel Registration)を使って OAuth 2.0 認証を行うことで Office365 のリソースにアクセスするように変更しています。

この構成の大きな流れは、名刺画像を Vision API でテキストに変換し(OCR 結果)、検索時に検索ワードをその OCR 結果から検索します。開発当初は Vision API の OCR 結果を更に Google Cloud Natural Language API(Natural Language API)を使って人名や会社名、住所などに分類してそれぞれ検索に使おうと考えていたのですが、Natural Language API の解析結果が期待したほどの精度ではなかった為、OCR 結果全文を保存しそれに対して検索をかける仕様にしました。
データは VPC 内に構築した GKE 上の Elasticsearch へ格納しています。Elasticsearch は GCP のアーキテクチャではありません。Elastic 社が提供するオープンソースの全文検索エンジンです。Elasticsearch は GCP 上でマネージドで提供もされていますがこちらは有料ですので、今回の名刺管理ボットではオープンソースを GKE 上で動かしています。そしてこの Elasticsearch が当名刺管理ボットを実用化レベルにする為のミソであったりします。
詳しくは後述しますが、Vison API で「高橋」が「髙橋(はしごだか)」と取り込まれてしまったりすることがありますが、Elasticsearch の機能を使用して 「高橋」でも「髙橋(はしごだか)」 でも検索がヒットするように出来ます。また、Vision API が正しく読み込んでいたとしても自分が検索したい「タカハシ」さんがどちらの漢字なのか中々覚えていないのではないでしょうか。Elasticsearch は形態素解析器 Sudachi を採用することで、こういった文字の揺れなどを変換して検索することが出来ます。この機能を使い OCR の精度が足らない部分を Elasticsearch の機能で補完しました。
以降では、アーキテクチャ毎に実装時のポイントを説明していきます。
Azure Bot Service Web App Bot 実装時のポイント
先ずは名刺管理ボットの最初の処理となる Web App Bot の実装時のポイントを説明します。ポイントとなるのは Azure から GCP のサービスの呼び出し方です。
GCP の API クライアントライブラリは、GCP 側にサービスアカウントを作成しそのサービスアカウントキーファイルを参照させることで、そのサービスアカウントに設定された権限で動作することが出来ます。参照方法は、クライアントライブラリが動作する環境の環境変数 GOOGLE_APPLICATION_CREDENTIALS に サービスアカウントキーファイル のパスを設定することで自動的に参照されます。
サービスアカウントキーファイルの作成方法
① GCP ポータルの IAMと管理 > サービスアカウント からサービスアカウントの作成を開始します。

②ロールに「Cloud Storage – Storage オブジェクト管理者」「Dialogflow – Dialogflow API クライアント」を設定します。その他の GCP サービスを使用する場合は必要に応じてロールを追加してください。

③この画面は特に何も設定せずに完了します。

④作成されたサービスアカウントを開き 鍵を追加 > 新しい鍵を作成 を行います。

⑤JSON タイプのファイルをダウンロードします。

環境変数の設定方法
Web App Bot への環境変数の設定は 構成 > アプリケーション設定 > 新しいアプリケーション設定 から行います。
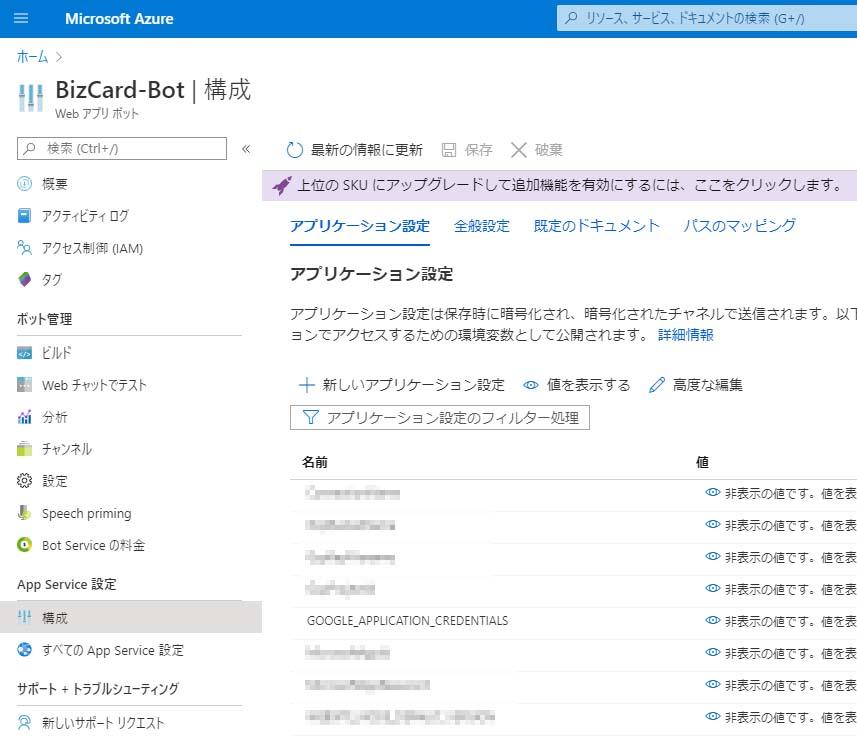
GOOGLE_APPLICATION_CREDENTIALS に サービスアカウントキーファイル のパスを設定してください。ボットソースが格納してあるディレクトリ直下にファイルを置いた場合はそこがルートになる為、環境変数の値はファイル名を設定するだけになります。
Azure から GCP API クライアントライブラリ呼び出しの実装例
ここまで準備が出来たら後はプログラムを実装するだけです。今回の名刺管理ボットでは Azure から Dialogflow と Cloud Storage を使用しているのでそれらの実装例を記載します。事前に環境変数 GOOGLE_APPLICATION_CREDENTIALS を設定しておくことで、Azure 上でも Cloud Functions 等と同様の記述で済みます。
Cloud Storage の実装例は以下の通りです。
const {Storage} = require('@google-cloud/storage');
const storage = new Storage();
・
・
・
await storage.bucket([バケット名]).upload([ファイル名], {gzip: false})
.then(res => {
return true;
})
.catch(err => {
return false;
});続いて Dialogflow の実装例です。
const dialogflow = require('dialogflow');
const sessionClient = new dialogflow.SessionsClient();
const projectId = [プロジェクトID];
const sessionId = [ユーザID];
const sessionPath = sessionClient.sessionPath(projectId, sessionId);
・
・
・
const request = {
session: sessionPath,
queryInput: {
text: {
text: [Dialogflowへ送信するテキスト],
languageCode: 'ja'
}
}
};
try {
const responses = await sessionClient.detectIntent(request);
return responses;
} catch (err) {
throw err;
}sessionPath 生成時にセッション ID にユーザ ID を設定しているのは、Dialogflow がこの値でクライアントを識別している為です。もしこの値を固定値にした場合、Dialogflow はどのユーザからの接続も同じユーザからの会話だと判断してしまいます。今回の名刺管理ボットでは Teams のユーザ ID を使用するようにしたので、Dialogflow はユーザ毎に会話を認識します。
Google Cloud Vision API 実装時のポイント
名刺管理を実現する肝となる Vision API の OCR 機能の実装のポイントを説明します。先ずは実装例を説明します。
API クライアントライブラリを使って Vision API にアクセスするクライアントのインスタンスを生成します。
const vision = require('@google-cloud/vision');
const visionClient = new vision.ImageAnnotatorClient();
・
・
・
let ret = null;
const request = {
image: {
source: {
imageUri: [Cloud Storage のパス gs://~]
}
}
};
//Vision API実行
const [result] = await visionClient.textDetection(request);
const texts = await result.textAnnotations;
if (texts.length != 0 && 'description' in texts[0]) {
ret = texts[0].description;
} else {
console.log('OCR失敗');
}Vision API は Cloud Storage のパスをそのまま渡せます。パラメータで名刺画像のパスを渡して ImageAnnotatorClient の textDetection を実行することで OCR 結果が得られます。
課題 日本語と英語が混在する名刺の OCR
ここでポイントとなったのが、Vision API の OCR 機能は TEXT_DETECTION と DOCUMENT_TEXT_DETECTION の2種類があり、ここでは TEXT_DETECTION を使っている点です。
この2つを簡単に比較した結果では名刺の読み込みに置いては大差が無いように思われた為、手書き文字やレイアウト情報等の認識が出来るより高機能な DOCUMENT_TEXT_DETECTION を使っていれば間違いはないだろうと思い使っていました。ところが日本語と英語が混在した名刺を読み込んだ時に問題が発生しました。(スキャナからの一括取り込みアップロード機能では名刺の裏面もスキャンし、表裏を一画像にしてから OCR を実行しています。この時に問題が発生しました。名刺の裏面って英語表記のものが多いですよね。)
日本語と英語が混在した時に DOCUMENT_TEXT_DETECTION では日本語を全く認識してくれなくなってしまいました。languageHints パラメータに日本語を設定しても、どうしても英語に引っ張られる様でした。
これを TEXT_DETECTION に変更したら問題なく読み込めるようになりました。ちなみに TEXT_DETECTION では languageHints パラメータは設定できません。言語の判定は Google 側で上手くやってくれるとの事でした。
課題 OCR の精度
日本語と英語の混在は何となく解決できましたがもう一つ問題がありました。それはそもそもの OCR の精度です。
「髙橋(はしごだか)」が「高橋」と読み込まれてしまったり、「奥田」が「奧田(旧字体)」と読み込まれてしまったりしました。前者は Google 側で辞書でも持っているのかな?と勝手に推測しますが、後者は読み込む名刺画像が汚れたり画像品質を下げ過ぎたりすると発生する様でした。
これらは名刺のフォント等にも依存するでしょうし必ずしも発生する訳ではありませんが、このままでは名刺を検索してもヒット出来ない為、対策が必要でした。
画像品質については処理の中で画像加工をする際に画像品質を下げ過ぎない様に調整が出来ますが、Vision API の OCR 結果を調整するのは難しい為、そこについては検索時の処理を工夫することで解決することにしました。そこで使用したのが全文検索エンジン Elasticsearch です。